
19.01.2026
Descubre qué es un data scientist y por qué tu negocio lo necesita
Qué tipo de perfil es un Data Scientist y cuándo tiene sentido contratar uno
Pedro Cailá

Un data scientist conecta los datos con las decisiones estratégicas del negocio. Su rol es convertir números crudos en una hoja de ruta clara para el producto. No se limita a analizar lo que ya pasó; su poder reside en construir modelos para anticipar el futuro y crear una ventaja competitiva real.
Qué es un data scientist en realidad
Un data scientist no es solo un analista de datos con más herramientas. Su función principal es formular las preguntas de negocio correctas, incluso las que nadie se había planteado, para luego usar datos y modelos para responderlas.
No se quedan en el "¿qué pasó?". Van directos al "¿qué va a pasar?" y, más importante aún, al "¿qué deberíamos hacer al respecto?".
Por ejemplo, un analista podría preparar un informe mostrando que las ventas cayeron un 15% el último trimestre. Un data scientist, en cambio, construiría un modelo para identificar qué clientes tienen más probabilidades de irse en los próximos 30 días. Esto permite al equipo de producto actuar antes de que el problema ocurra.
Más allá de los algoritmos
Aunque crear algoritmos de machine learning es parte del trabajo, el valor real nace de su capacidad para entender el contexto del negocio.
Un buen data scientist invierte la mayor parte de su tiempo en tareas críticas:
- Entender el problema de raíz: Antes de escribir una línea de código, se centra en entender qué métrica de negocio se quiere mover y por qué es importante.
- Limpiar y preparar los datos: Gran parte del trabajo (hasta un 80%) consiste en explorar, limpiar y preparar los datos. Esto significa lidiar con valores que faltan, corregir formatos y asegurarse de que las fuentes son fiables.
- Contar una historia con los resultados: De nada sirve el mejor modelo del mundo si nadie lo entiende. Una habilidad clave es traducir hallazgos técnicos en una narrativa sencilla y accionable para perfiles no técnicos, como product managers o directivos.
Un buen modelo predictivo que no resuelve un problema de negocio real o que nadie en el equipo entiende, es inútil. El impacto de un data scientist se mide por las decisiones que sus insights provocan.
Un data scientist se mueve en la intersección de tres mundos: estadística, informática y conocimiento profundo del negocio. Su objetivo final no es generar análisis, sino construir sistemas y productos basados en datos que generen un impacto medible.
Resumen rápido del rol del data scientist
Esta tabla resume las áreas clave donde un data scientist aporta valor, qué hace exactamente y cómo impacta en los resultados.
Modelado predictivo:
Esta área se centra en construir modelos que anticipen comportamientos futuros, como la probabilidad de que un cliente abandone (churn) o las ventas esperadas. Su impacto en el negocio es significativo, ya que permite tomar decisiones proactivas, reducir costes y generar nuevas oportunidades de ingresos.
Experimentación y A/B Testing:
Consiste en diseñar y analizar experimentos para validar hipótesis de producto o marketing. Su valor radica en asegurar que las decisiones se basen en evidencia, optimizando la conversión y mejorando la efectividad de estrategias comerciales o de producto.
Descubrimiento de insights:
Se trata de explorar grandes volúmenes de datos para identificar patrones y oportunidades que no son evidentes a simple vista. Esto puede revelar nuevos segmentos de mercado, optimizar operaciones o descubrir palancas de crecimiento hasta ahora desconocidas.
Comunicación estratégica:
Implica traducir los hallazgos técnicos en recomendaciones claras y accionables para el negocio. Esta área garantiza que los datos se utilicen para guiar la estrategia de la empresa y alinear a todos los equipos en torno a objetivos comunes.
Este perfil estratégico necesita tanto rigor analítico como una gran capacidad para entender y comunicar el valor de negocio.
Cómo es el día a día de un data scientist de alto impacto
El día a día de un data scientist de alto impacto es dinámico y colaborativo. Es un ciclo que empieza con una pregunta de negocio y termina con resultados medibles.
Pasa el día en reuniones con product managers para definir problemas, con ingenieros para entender el origen de los datos y con stakeholders para explicar los resultados de forma comprensible.
El ciclo de vida de un proyecto de datos
Todo proyecto sigue una secuencia lógica, aunque rara vez es lineal. Es un bucle de aprendizaje constante para encontrar la mejor solución a un problema concreto.
Un data scientist puede dedicar hasta el 80% de su tiempo a buscar, limpiar y preparar los datos. El 20% restante es para el modelado y el análisis.
Aunque la fase de preparación es la menos glamurosa, es la más crítica. Un modelo complejo construido sobre datos de mala calidad solo producirá resultados erróneos que pueden llevar a decisiones de negocio desastrosas.
El siguiente diagrama simplifica este proceso en tres fases, mostrando el flujo desde el dato en bruto hasta su aplicación estratégica.
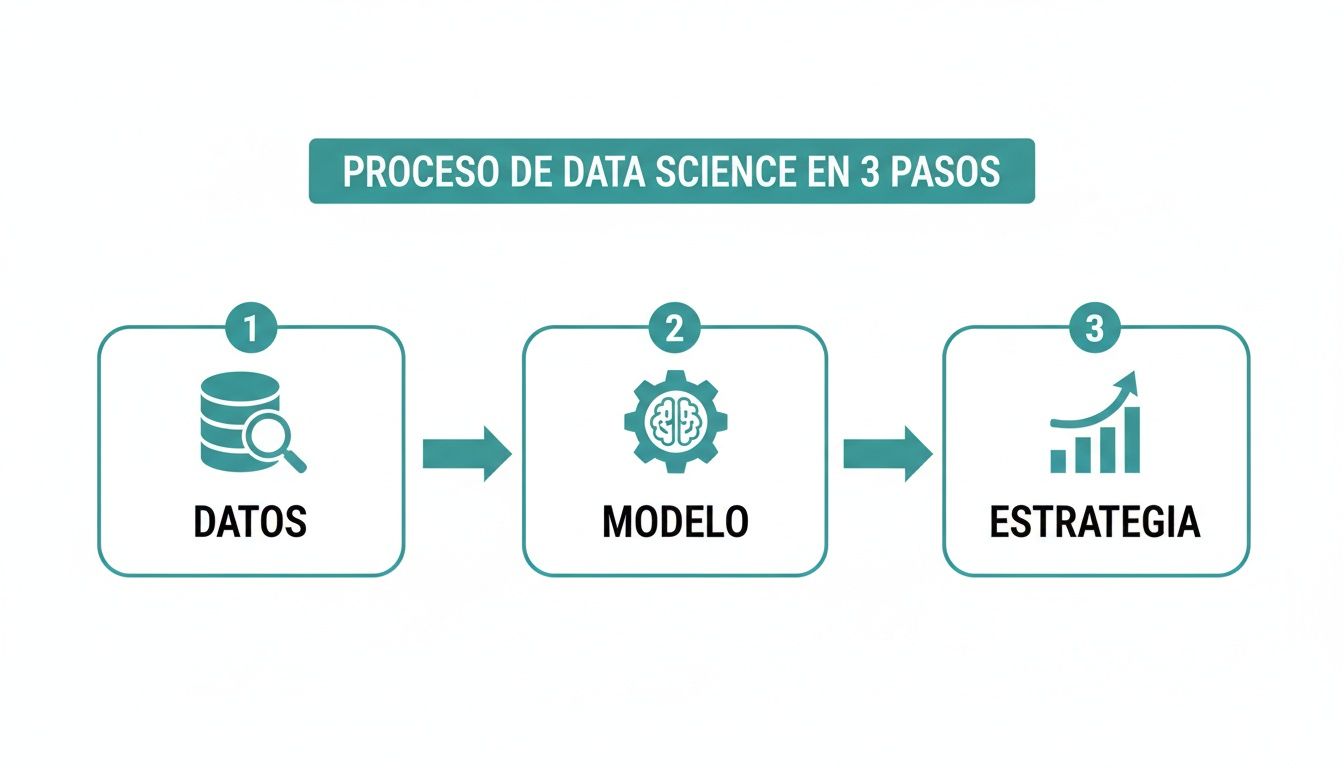
Todo arranca con los datos, evoluciona hacia un modelo y culmina aplicando una estrategia que genera valor.
De la pregunta a la acción
Veamos un caso práctico. Una empresa quiere saber qué clientes tienen más riesgo de darse de baja (churn).
- Definición del problema: Se define qué significa exactamente "darse de baja" junto al equipo de producto. ¿Es un usuario que no entra en la app en 30 días o uno que cancela su suscripción?
- Recolección y limpieza de datos: Se extraen historiales de uso o compras con consultas SQL. Después viene la limpieza: corregir valores faltantes, unificar formatos y eliminar ruido.
- Análisis exploratorio (EDA): Se exploran los datos limpios para encontrar patrones. Visualizar los datos en esta fase es fundamental para generar las primeras hipótesis.
- Modelado y validación: Se entrenan varios algoritmos de machine learning para ver cuál predice mejor el churn y se valida su rendimiento para asegurar que puede generalizar a futuro.
- Comunicación y despliegue: Se presentan los hallazgos. No se dice "el modelo tiene una precisión del 92%". Se explica qué factores influyen en la fuga de clientes y se proponen acciones, como lanzar una campaña de retención para usuarios en riesgo. Este paso convierte un análisis técnico en impacto real.
El stack tecnológico y las habilidades que definen a un gran perfil
Dominar las herramientas es necesario, pero no suficiente. Un gran data scientist combina conocimiento técnico profundo con habilidades blandas que le permiten transformar análisis en acciones de negocio.

La mezcla de estas dos facetas, la técnica y la humana, diferencia a un perfil que ejecuta tareas de otro que impulsa el crecimiento.
Las competencias técnicas fundamentales
Aunque el stack tecnológico puede variar, hay un núcleo de herramientas base.
- Python como lengua franca: Es el estándar por su simplicidad y sus librerías. Pandas para la manipulación de datos, NumPy para cálculos numéricos y Scikit-learn para machine learning son indispensables.
- SQL para el acceso a datos: El dominio de SQL es innegociable para consultar bases de datos y obtener los datos necesarios para cualquier proyecto.
- Herramientas de visualización: Es crucial saber visualizar datos para explorarlos y comunicar resultados. Librerías como Matplotlib o Seaborn son comunes, al igual que herramientas de BI como Tableau o Power BI.
- Conocimiento del cloud: Tener experiencia con plataformas en la nube como AWS, GCP o Azure es cada vez más importante para llevar los proyectos a producción.
Más importante que las herramientas es entender los fundamentos: estadística, álgebra lineal y los principios del machine learning.
Habilidades blandas que marcan la diferencia
Las herramientas cambian, pero las habilidades blandas perduran y definen el impacto de un data scientist.
Un modelo técnicamente perfecto que no resuelve un problema real del negocio es un ejercicio académico, no una solución empresarial. La capacidad de conectar el análisis con la estrategia es lo que distingue a los mejores perfiles.
Estas son las tres habilidades clave:
- Curiosidad y pensamiento crítico: Un buen profesional de datos cuestiona los datos, busca sesgos, se pregunta por qué faltan valores y formula hipótesis.
- Visión de negocio: Es la capacidad de entender qué métricas importan y cómo un proyecto de datos puede moverlas. Implica hablar el idioma de producto, marketing o finanzas.
- Storytelling con datos: Es la habilidad de construir una narrativa clara y convincente a partir de los datos para guiar a los stakeholders hacia una decisión informada.
La transformación digital posiciona al data scientist como una profesión clave. En 2022, solo el 11% de las empresas en España utilizaba análisis de Big Data, pero la meta del plan España Digital 2026 es alcanzar el 25%. Esta demanda se refleja en salarios con una mediana de 55.400 € y perfiles sénior que superan los 85.000 €. Para puestos de IA, puedes leer sobre qué perfil de IA necesita tu equipo.
Un gran data scientist no solo sabe construir modelos; sabe qué modelos construir y por qué.
Diferencias clave con otros roles del ecosistema de datos
Confundir los roles del ecosistema de datos es un error de contratación común y caro. Contratar a un data scientist para construir pipelines de datos o a un analista para crear modelos predictivos complejos lleva a la frustración y a resultados mediocres.
Cada perfil resuelve un tipo de problema distinto. No se trata de qué rol es "mejor", sino de cuál necesitas según la madurez de tu producto y tus datos.
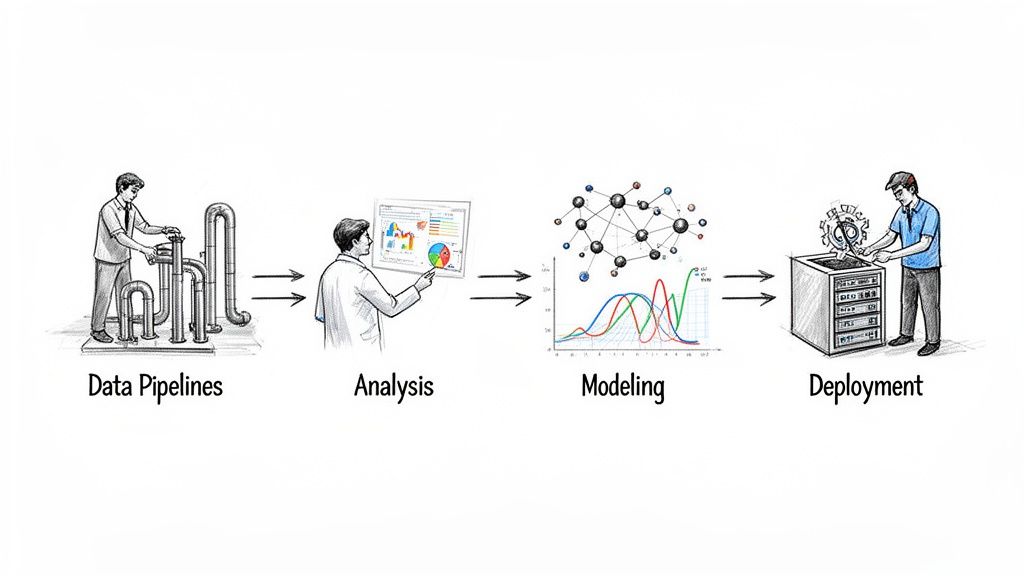
La cadena de valor del dato
Una buena forma de entenderlo es pensar en el flujo de datos como una cadena de montaje donde cada rol se encarga de una fase específica.
- El Data Engineer construye la infraestructura: las "tuberías" y almacenes para que los datos fluyan de forma fiable y escalable.
- El Data Analyst usa esos datos para generar informes y dashboards, explorando lo que ya ha ocurrido.
- El Data Scientist entra en juego para predecir el futuro, usando los datos para construir modelos de machine learning.
- El Machine Learning Engineer se asegura de que esos modelos funcionen en el mundo real, convirtiendo prototipos en productos robustos. Puedes aprender más sobre perfiles híbridos en nuestro artículo sobre qué es un full stack developer en nuestro artículo.
La principal diferencia reside en el horizonte temporal: un analista mira al pasado, un científico de datos mira al futuro. El primero describe la realidad; el segundo, la predice para poder cambiarla.
Comparativa de roles en el ecosistema data
Esta tabla resume las responsabilidades, herramientas y objetivos de cada perfil para ver las distinciones de un vistazo.
Data Engineer:
El data engineer se encarga de construir y mantener la infraestructura de datos de una organización, como los procesos ETL y los data warehouses. Su trabajo asegura que los datos estén disponibles, limpios y sean accesibles para otros equipos. Utiliza herramientas como Spark, Kafka, Airflow, SQL y Python. La pregunta clave que responde este rol es: “¿Están los datos disponibles, limpios y accesibles?”
Data Analyst:
El data analyst analiza datos históricos para encontrar tendencias, patrones y generar informes que apoyen la toma de decisiones. Trabaja habitualmente con SQL, Tableau, Power BI y Excel. Su enfoque se centra en entender el pasado, respondiendo a la pregunta: “¿Qué ha pasado y por qué?”
Data Scientist:
El data scientist utiliza estadística y técnicas de machine learning para predecir resultados futuros y proponer acciones basadas en datos. Sus herramientas más comunes incluyen Python (con librerías como Scikit-learn), R y SQL. Este rol responde a preguntas como: “¿Qué pasará y qué podemos hacer al respecto?”
ML Engineer:
El machine learning engineer se ocupa de desplegar, monitorizar y mantener modelos de machine learning en producción, asegurando que funcionen de forma eficiente y a gran escala. Suele trabajar con tecnologías como Docker, Kubernetes y AWS SageMaker. La pregunta que guía su trabajo es: “¿Cómo hacemos que este modelo funcione a escala?”
Diferencias salariales y enfoque de negocio:
La diferencia en el enfoque predictivo del data scientist se refleja también en el salario. En España, la brecha salarial entre data analytics y data science favorece a los perfiles de data science. Un data scientist júnior suele tener un rango salarial de entre 28.000 € y 35.000 €, mientras que un data analyst con la misma experiencia se sitúa aproximadamente entre 24.000 € y 30.000 €. Esta diferencia se vuelve aún mayor en perfiles sénior.
En definitiva, saber qué pregunta de negocio quieres resolver te permitirá identificar con claridad qué perfil profesional necesitas.
¿Cuándo (y cómo) contratar a tu primer data scientist?
Fichar a un data scientist demasiado pronto es tirar el dinero. Hacerlo demasiado tarde es regalar una ventaja competitiva. El momento adecuado depende de la madurez de tus datos y la claridad de tus preguntas de negocio.
El momento ideal llega cuando tu equipo ya no puede responder preguntas críticas con análisis sencillos. Es el punto en el que pasas de necesitar dashboards que te digan el "qué pasó" a necesitar modelos que predigan el "qué pasará".
Contrata cuando tengas un problema de negocio tan definido que la ciencia de datos pueda aportar una solución tangible, como "necesitamos optimizar nuestros precios" o "queremos reducir el abandono de clientes un 10%".
Señales de que ha llegado la hora
Si te identificas con estas situaciones, es probable que sea el momento de buscar.
- Acumulas datos, pero no insights. Tienes logs y datos de uso, pero nadie sabe qué hacer con ellos más allá de métricas básicas.
- Decisiones basadas en la intuición. Tu equipo toma decisiones importantes basándose en "sensaciones" en lugar de en experimentos A/B rigurosos.
- Preguntas sin respuesta. Surgen dudas como "¿qué clientes son más valiosos a largo plazo?", pero no tenéis forma de responderlas con datos.
Un error común es contratar a un data scientist esperando que haga magia con datos desordenados y sin infraestructura. Antes de lanzar la oferta, asegúrate de tener datos accesibles y un problema de negocio claro.
Checklist para la entrevista perfecta
El objetivo es poner a prueba sus habilidades técnicas, su visión de producto y su encaje cultural. Los mejores candidatos son excelentes resolviendo problemas de negocio.
Combina preguntas técnicas con casos prácticos de tu empresa:
- Fundamentos técnicos:
- Pídele que hable de un proyecto del que se sienta orgulloso y explique los trade-offs técnicos que asumió.
- Plantea un problema teórico sencillo: "explícame la diferencia entre sesgo y varianza como si yo no supiera nada del tema".
- Dale un problema real: "Queremos predecir qué usuarios gratuitos tienen más probabilidades de convertirse en clientes de pago. ¿Cómo lo enfocarías?".
- Mide su curiosidad: ¿Qué preguntas te hace sobre tus datos y tu producto?
- Rétale a explicar un concepto técnico complejo a alguien sin conocimientos técnicos, como un director de marketing.
- Fíjate en cómo estructura sus ideas y si es capaz de simplificar sin perder rigor.
Una buena entrevista te dejará claro no solo lo que el candidato sabe hacer, sino cómo piensa y qué impacto podría tener.
¿Cuánto gana un data scientist en España?
Entender la compensación de un data scientist es clave para no perder candidatos con ofertas fuera de mercado. Los salarios son competitivos porque la demanda es alta y hay escasez de profesionales con experiencia demostrada.
La remuneración varía según la experiencia y la ubicación. Madrid y Barcelona lideran los salarios, pero ciudades como Málaga o Valencia están en plena expansión.
Salarios por nivel de experiencia
A medida que un profesional gana autonomía y demuestra un impacto directo en el negocio, su valor aumenta. Un perfil júnior necesita supervisión, mientras que un sénior lidera proyectos de principio a fin.
El rol de data scientist es uno de los perfiles tecnológicos mejor pagados en España.
- Júnior (0-2 años): entre 25.000 € y 35.000 € anuales.
- Mid (2-5 años): entre 36.000 € y 50.000 €.
- Sénior (5-10 años): entre 51.000 € y 70.000 €.
- Expertos (+10 años): superan los 71.000 € y pueden llegar a 100.000 € en roles de liderazgo.
-
Estos datos, basados en la Guía Salarial 2026, te dan una foto fiel del mercado. Tener estos benchmarks a mano es fundamental para que tu oferta sea atractiva.
Preguntas frecuentes sobre el rol de data scientist
Para cerrar, respondemos a las dudas más comunes antes de contratar a tu primer data scientist.
¿Necesito un data scientist si ya tengo un data analyst?
Sí, si quieres dejar de mirar solo lo que ya pasó para empezar a predecir lo que va a pasar. No son roles que compiten, se complementan. Un analista te dará informes sobre el rendimiento pasado. El científico de datos construye modelos de machine learning para optimizar el futuro, como predecir qué clientes están a punto de irse o crear un sistema de recomendaciones.
¿Qué impacto real puede tener en una startup en sus primeros 6 meses?
En seis meses, un buen data scientist puede ahorrarte tiempo y dinero validando hipótesis de negocio. Su primer impacto no tiene por qué ser un modelo complejo. Puede empezar por identificar los KPIs clave, construir un primer modelo predictivo para un problema concreto (como optimizar precios) e instalar una cultura de experimentación basada en datos.
El valor de un data scientist en una fase temprana es demostrar con datos qué ideas de producto merecen la pena y cuáles no, evitando meses de desarrollo en la dirección equivocada.
¿Es mejor contratar un perfil generalista o uno especializado al principio?
Para tu primera contratación, un data scientist generalista es casi siempre la apuesta más segura. Necesitas a alguien que no le tenga miedo a ensuciarse las manos en todo el ciclo del dato: desde la extracción y limpieza hasta comunicar los resultados a perfiles no técnicos. Un perfil demasiado especializado podría frustrarse si la infraestructura de datos no está madura. Ya habrá tiempo para traer especialistas. Primero necesitas a alguien que construya las bases y demuestre el valor del dato.
En Kulturo, conectamos a empresas como la tuya con el talento tecnológico que necesitan para crecer. Si buscas un data scientist que no solo domine la técnica sino que entienda tu negocio, podemos ayudarte a encontrarlo.




