
23.05.2026
Testing automatizado: la guía para startups y scaleups
Hemos llevado muchísmimos perfiles de testing automatizado para startups/scaleups. Te explicamos la importancia de este rol.
Pedro Cailá

El viernes por la tarde sale una release pequeña. En teoría, era un cambio seguro. Un ajuste en pricing, una mejora en onboarding, una modificación menor en permisos. El lunes por la mañana hay tickets, soporte está desbordado y alguien descubre que el cambio ha roto un flujo básico del producto.
Ese momento no suele revelar un bug aislado. Revela una organización que todavía valida demasiado tarde, demasiado manualmente y con demasiada confianza en que “ya lo miramos antes de desplegar”. En una startup o scaleup, ese patrón sale caro porque el producto cambia rápido, el equipo toca muchas capas a la vez y nadie tiene margen para montar un comité de guerra por cada regresión.
Ahí es donde el testing automatizado deja de ser una conversación de QA y pasa a ser una decisión de negocio. No sirve solo para detectar fallos. Sirve para proteger velocidad, reputación y foco del equipo. Cuando funciona bien, evita que cada release dependa de la memoria de una persona o de una checklist improvisada en Slack.
En España, además, la adopción no va de moda técnica sino de presión operativa. El testing automatizado se ha consolidado como una capa clave de verificación del software y el mercado global de pruebas de automatización se ha valorado en 24.250 millones de dólares en 2026, según The Power Education. Ese contexto explica por qué tantas compañías tecnológicas están acelerando su adopción.
Introducción Cuando un bug te cuesta clientes
Un CTO no suele pedir “más testing”. Pide algo más concreto y más incómodo: dejar de perder ventas por errores evitables, dejar de enterarse por soporte de que el login falla y dejar de tratar cada release como una apuesta.
Ese es el punto de partida real en una startup o scaleup. El problema no es la falta de teoría sobre calidad. El problema es que cada cambio en pricing, onboarding, permisos o checkout puede romper un flujo que impacta ingresos, retención o confianza del cliente. En equipos pequeños, además, el coste no se queda en el bug. Se va en interrupciones, foco perdido, decisiones retrasadas y horas senior dedicadas a validar manualmente lo que una suite bien planteada debería cubrir.
El testing automatizado se adopta para reducir riesgo operativo y proteger la velocidad de entrega.
Cuando esa capa no existe, aparecen patrones muy previsibles. El equipo retrasa despliegues porque nadie conoce bien el impacto real de un cambio. Dos o tres personas se convierten en cuello de botella porque “ya saben qué revisar”. Y ciertas regresiones vuelven una y otra vez porque la organización confía en memoria humana, no en comprobaciones repetibles.
Una release frecuente sin validación fiable no acelera el negocio. Solo multiplica el coste de cada cambio.
He visto este error muchas veces en compañías que están creciendo rápido en España. Invierten en nuevas features, en performance y en contratación, pero mantienen el control de calidad en checklists manuales, smoke tests improvisados y revisiones de última hora. Funciona durante un tiempo. Luego llegan más integraciones, más perfiles tocando producción y más presión comercial por sacar cosas antes. En ese contexto, probar “al final” deja de ser una incomodidad técnica y pasa a ser un problema de gestión.
La mala decisión habitual consiste en responder con un plan demasiado ambicioso. Cien tests end-to-end, una herramienta nueva y la expectativa de cubrir todo en dos sprints. Ese enfoque casi siempre falla por una razón simple: genera más mantenimiento del que el equipo puede absorber. La alternativa sensata es priorizar por riesgo. Empezar por los flujos que mueven dinero, activación o soporte. Medir estabilidad. Ajustar cobertura. Contratar a gente que entienda producto, arquitectura y costes de mantenimiento, no solo herramientas.
Lo que un CTO necesita decidir
La conversación útil no gira alrededor de si “hay que hacer testing automatizado”. Gira alrededor de cuatro decisiones de negocio:
- Cuándo invertir. No todas las fases de producto justifican el mismo nivel de automatización.
- Qué proteger primero. Los tests deben seguir el mapa de riesgo del negocio, no una pirámide aplicada de forma dogmática.
- Qué talento hace falta. Un equipo no mejora su calidad por añadir una persona de QA si desarrollo sigue entregando código sin estrategia de verificación.
- Cómo usar IA sin degradar la suite. La IA ayuda a generar casos, detectar patrones y acelerar mantenimiento, pero también puede producir tests frágiles y ruido si nadie revisa el diseño.
Para una startup, la pregunta correcta no es si puede permitirse invertir en testing automatizado. La pregunta correcta es cuánto le cuesta seguir creciendo sin esa disciplina.
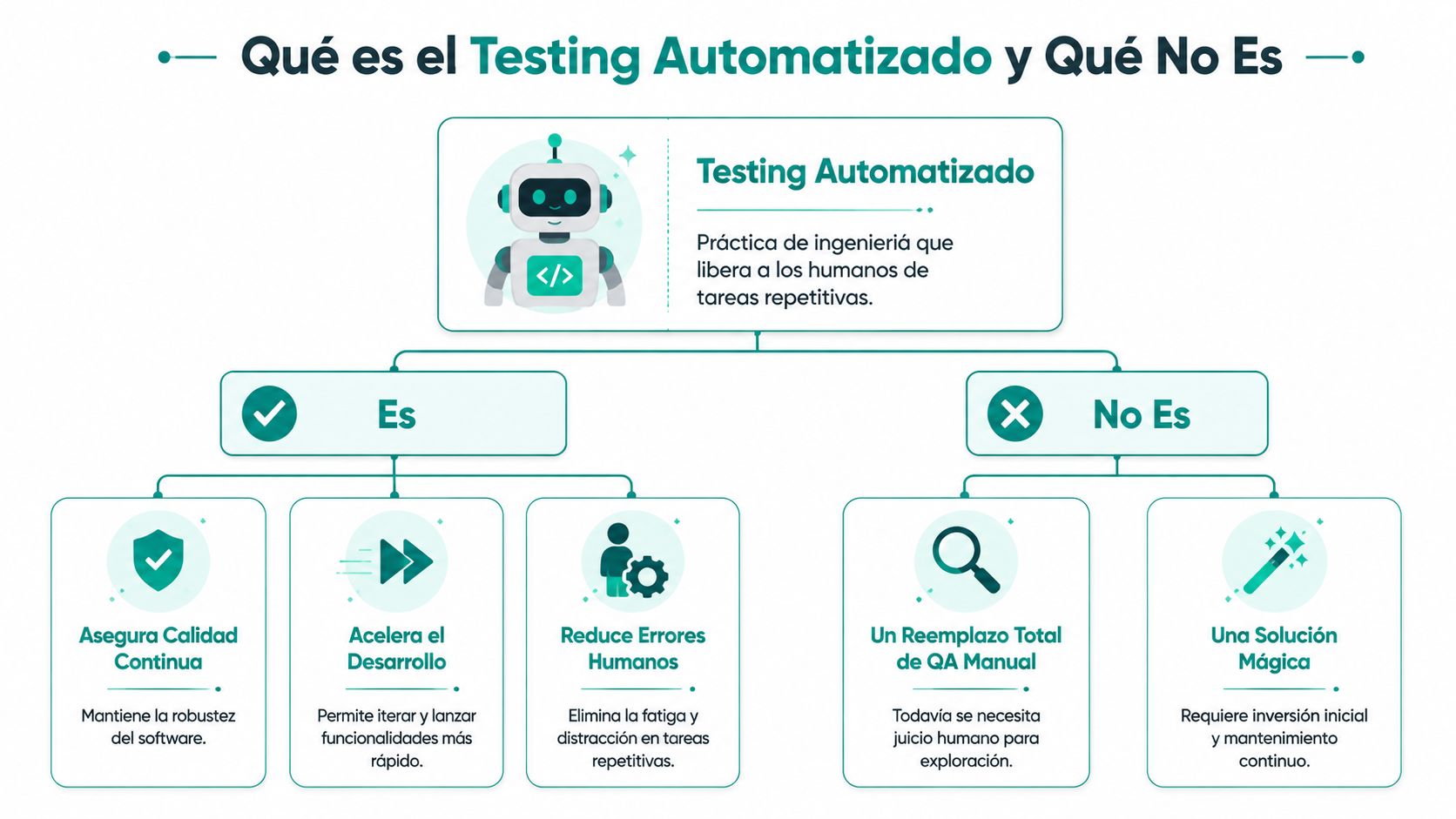
Qué es el testing automatizado y qué no es
El testing automatizado convierte comprobaciones repetibles del producto en software que se ejecuta de forma consistente dentro del ciclo de entrega. Su utilidad real para un CTO no está en acumular tests ni en perseguir una cifra de cobertura. Está en reducir el coste de validar cambios, detectar regresiones antes de producción y dar al equipo una base fiable para desplegar con más frecuencia.
En un producto digital, eso suele traducirse en suites que verifican lógica de negocio, contratos entre servicios, APIs, flujos de usuario y, en algunos casos, rendimiento. Herramientas como Selenium, Cypress, Playwright, Postman o Apache JMeter resuelven partes distintas del problema. La herramienta importa menos que la intención. Un mal criterio con una tecnología moderna sigue produciendo una suite cara, lenta y frágil.
Conviene entender qué compra de verdad esta inversión. Testing automatizado compra velocidad de feedback, repetibilidad y memoria técnica. Si un bug de facturación ya ocurrió, el equipo puede dejar una prueba que lo bloquee para siempre o hasta que alguien cambie deliberadamente esa regla. Ese es el activo. No sustituye la conversación entre producto, ingeniería y negocio, pero evita volver a pagar por el mismo fallo.
También cambia cómo trabaja el equipo. Las personas dejan de gastar tiempo en repetir checks mecánicos en cada release y pueden dedicarlo a explorar casos ambiguos, revisar impactos de negocio o investigar comportamientos raros que una prueba predefinida no cubriría. Por eso automatizar no elimina el testing manual. Lo vuelve más valioso.
Prometeo lo explica bien en su análisis sobre testing automatizado: el trabajo manual y el automatizado se complementan porque responden a riesgos distintos. Una suite automática ejecuta lo que ya se conoce y se quiere proteger. La revisión humana sigue siendo útil para cambios de UX, requisitos poco maduros, edge cases y decisiones que todavía no están del todo cerradas.
Hay otro punto que en startups y scaleups suele ignorarse hasta que duele. Los tests también son código y generan mantenimiento. Si el producto cambia cada semana, la suite debe evolucionar al mismo ritmo. Si la arquitectura está muy acoplada, si el front depende de selectores inestables o si los entornos no son fiables, automatizar se vuelve más caro. La consecuencia no es “no automatices”. La consecuencia es automatiza donde el retorno sea claro y corrige primero los cuellos de diseño que vuelven frágil la verificación.
Por eso desconfío de dos promesas. La primera es que una batería de E2E va a darte confianza total. La segunda es que la IA va a generar una suite útil sin criterio técnico fuerte detrás. Los modelos ayudan a redactar casos, crear datos de prueba o acelerar refactors de tests. También producen checks redundantes, assertions débiles y mucho ruido si nadie define qué riesgo merece protección.
La referencia práctica sigue siendo simple: cuanto más abajo pruebes una regla, más barato suele ser detectar y diagnosticar el fallo. La test pyramid sigue teniendo sentido por una razón económica, no dogmática. Una base amplia de tests unitarios y de integración suele dar mejor señal que una colección enorme de pruebas de interfaz. Los E2E tienen sitio, pero en una capa pequeña, reservada para journeys donde un fallo afecta ingresos, activación o soporte.
Si una iniciativa de testing se presenta como una compra de herramientas, está mal planteada. Si se plantea como una forma de reducir riesgo operativo, acortar feedback y proteger flujos críticos mientras el equipo escala, entonces sí estás hablando de una capacidad de ingeniería que merece inversión.
Los tipos de tests que tu producto necesita
El catálogo de tests no se decide por madurez técnica ni por seguir una plantilla de libro. Se decide por riesgo económico. Si un bug en pricing te hace perder margen, protege pricing. Si una rotura en onboarding frena activación, protege onboarding. Si una integración con pagos o facturación genera tickets y retrabajo, protege ese contrato antes que cualquier otra cosa.
La discusión útil para un CTO no es “¿tenemos unitarios, integración y E2E?”. La pregunta correcta es otra: “¿qué fallos nos cuestan ingresos, confianza del cliente o tiempo operativo, y cuál es la forma más barata de detectarlos antes de producción?”. Con ese criterio, cada tipo de test ocupa un sitio distinto.
Tests unitarios
Los unitarios validan reglas de negocio en aislamiento. Son la mejor opción para cálculos, validaciones, permisos, asignación de planes, límites de uso o cualquier lógica que deba seguir funcionando aunque cambie la interfaz o la base de datos.
Aquí suele estar el ROI más claro al principio. Un test unitario bien escrito corre rápido, falla cerca de la causa y permite refactorizar sin miedo. En equipos pequeños, eso importa mucho porque cada cambio lo toca la misma gente que luego atiende incidencias.
Un ejemplo sencillo. Si tu SaaS aplica descuentos por plan, país, volumen y fecha de renovación, esa lógica debería poder probarse con datos de entrada y salida esperada. No hace falta levantar media plataforma para saber si una regla de pricing está mal.
También conviene decir qué no son. No son útiles para demostrar que dos servicios hablan bien entre sí. No sirven para validar queries reales, colas, permisos de infraestructura o flujos de navegador. Si se fuerzan para cubrir eso, generan una sensación de seguridad que luego desaparece en staging o en producción.
Tests de integración
Los tests de integración comprueban que dos o más piezas colaboran como deben. API y base de datos. Servicio y cola. Backend y proveedor externo. Módulo de autenticación y sistema de permisos.
En muchas startups, esta capa está infrainvertida. Es un error común. El fallo costoso no suele estar en una función pura, sino en un contrato que cambió, una serialización incorrecta, una migración mal aplicada o una dependencia externa que responde de forma distinta a la esperada.
Por eso, en productos con arquitectura distribuida o con varias integraciones de negocio, los tests de integración suelen dar mejor señal que ampliar una suite E2E sin criterio. Si tu equipo trabaja con Python o Java en backend, el enfoque y la profundidad de esta capa también cambian según el stack y la madurez del runtime. Merece la pena revisar diferencias prácticas entre ambos en esta comparación de Python vs Java para sistemas backend.
Un caso típico. El endpoint de alta crea usuario, escribe en la base de datos, publica un evento y devuelve una respuesta con permisos iniciales. Eso no es unitario. Tampoco hace falta abrir un navegador para cubrirlo bien.
Tests end to end
Los E2E validan recorridos completos desde la perspectiva del usuario. Registro, login, compra, recuperación de contraseña, upgrade de plan, cancelación, descarga de factura. Son los más cercanos al negocio y también los más caros de mantener.
Aquí conviene ser selectivo. Un E2E merece la pena cuando protege un flujo cuya caída se nota en ingresos, activación o volumen de soporte. Si el journey falla y el equipo se entera por clientes, ese flujo merece automatización. Si solo confirma un detalle de UI sin impacto real, está ocupando presupuesto de mantenimiento donde no toca.
He visto suites E2E crecer demasiado pronto en startups que todavía estaban cambiando producto cada semana. El resultado suele ser previsible. Builds lentas, falsos negativos, desconfianza en CI y gente reejecutando tests hasta que “sale verde”. Eso no es confianza. Es fricción operativa.
La regla práctica es simple. Pocos E2E, pero muy bien elegidos.
Tests de regresión
Regresión no es una tecnología concreta. Es una decisión de protección. Consiste en automatizar aquello que ya se rompió o aquello que sería caro romper mañana.
Esta capa suele ser la más política dentro de un equipo, porque obliga a admitir dónde existe deuda. Si cada release toca autenticación, permisos, checkout, facturación o una API compartida con clientes, esa zona necesita checks repetibles en cada entrega. No por estética de ingeniería. Por coste de error.
Un buen criterio para decidir qué entra en regresión es mirar tres señales: frecuencia de cambio, impacto del fallo y dificultad de detección manual. Cuando esas tres suben a la vez, automatizar deja de ser opcional y pasa a ser una inversión sensata.
Cómo repartir esfuerzo sin desperdiciar presupuesto
La distribución razonable en una startup rara vez es uniforme. Conviene concentrar esfuerzo donde el producto pierde dinero o velocidad si algo falla.
- Reglas de negocio con muchas combinaciones. Prioriza unitarios.
- Puntos donde se conectan servicios, colas, BBDD o proveedores. Prioriza integración.
- Journeys que afectan conversión, activación, cobro o autoservicio del cliente. Añade E2E.
- Áreas con historial de incidentes o cambios frecuentes. Conviértelas en regresión automatizada.
El error no es tener pocos tests de un tipo u otro. El error es gastar meses en automatizar zonas baratas de revisar manualmente mientras quedan sin proteger los flujos que sí frenan al negocio.
Frameworks y herramientas para tu stack tecnológico
La mayoría de equipos pierde tiempo comparando herramientas como si la decisión fuese irreversible. No lo es. Lo importante es elegir algo que el equipo pueda adoptar rápido, entender bien y mantener sin montar una religión interna.

JavaScript y TypeScript
Si tu stack es React, Next.js, Node.js o una combinación similar, la conversación real suele ser Cypress vs Playwright.
Cypress sigue siendo cómodo para equipos frontend porque la experiencia de desarrollo es muy accesible y la depuración resulta bastante directa. Para producto web puro y equipos que quieren ponerse en marcha deprisa, sigue siendo una opción razonable.
Playwright suele encajar mejor cuando buscas más versatilidad, mejor cobertura multi-browser y una base más sólida para pruebas modernas de UI y flujos complejos. Si hoy montara una suite nueva para una startup con ambición de escalar, mi sesgo sería Playwright antes que Cypress.
Selenium no está muerto, pero para una startup rara vez es la primera recomendación. Tiene sentido en contextos más heredados o cuando ya existe experiencia fuerte en el equipo. Si partes de cero, normalmente hay opciones más ágiles.
Python
En backend Python, Pytest es la elección más fácil de defender. Es legible, flexible y funciona muy bien para unitarios e integración. En Django o FastAPI, permite escribir pruebas con poco ruido y una curva de entrada razonable.
Si tu backend principal está en Python y estás comparando lenguajes para futuras contrataciones, puede ayudarte esta comparación entre Python y Java en equipos de producto.
Para APIs, combinar Pytest con clientes HTTP de prueba y fixtures bien diseñadas suele dar muy buen resultado. La clave no es la herramienta. Es evitar fixtures barrocas y tests que dependan de demasiado contexto oculto.
Java y Kotlin
En este ecosistema, JUnit sigue siendo la base natural. Añade Mockito cuando necesites aislar dependencias y validar comportamiento sin levantar medio sistema. No hay glamour aquí, pero sí madurez y predictibilidad.
Si el producto tiene una base enterprise, integraciones complejas o un legado importante, Java y Kotlin permiten construir suites muy serias. El riesgo no está en el stack, sino en caer en exceso de abstracción y hacer que cada test parezca un framework dentro de otro framework.
La recomendación honesta
Para una startup, el criterio debería ser este:
- Elige herramientas populares en tu stack. Facilitan hiring y onboarding.
- Evita combinaciones exóticas salvo que resuelvan un dolor muy real.
- Optimiza para mantenimiento, no para demos espectaculares.
- No abras tres frentes a la vez. Una herramienta por problema suele bastar.
La mejor suite no es la más sofisticada. Es la que el equipo ejecuta, entiende y corrige sin drama.
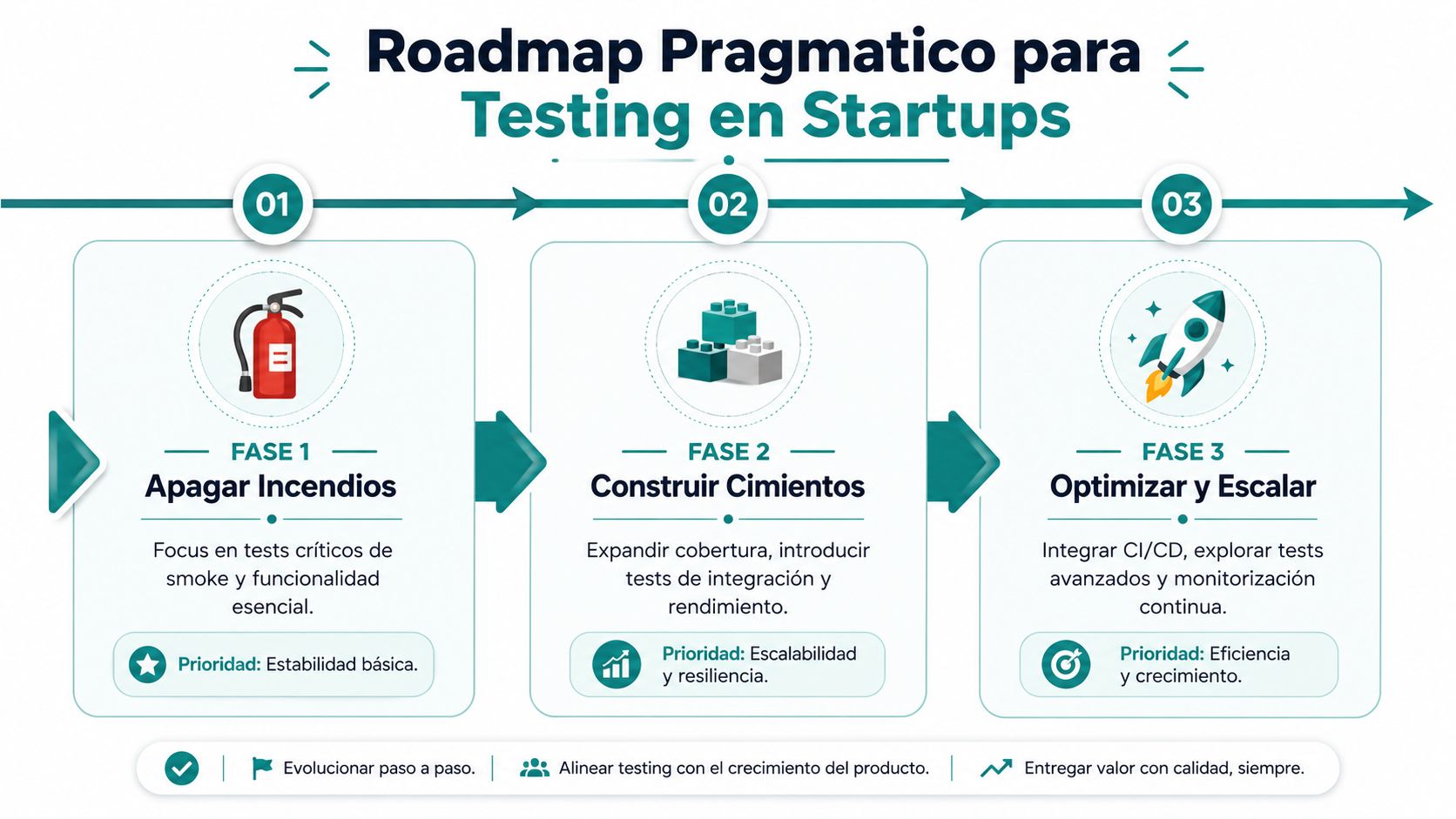
Un roadmap pragmático para implementar testing en tu startup
La peor forma de adoptar testing automatizado es convertirlo en una iniciativa abstracta. “Vamos a mejorar calidad” no sirve. “Vamos a proteger login, checkout y la API de facturación antes del próximo ciclo” sí sirve.
En pymes y scaleups en España, la pregunta crítica es el ROI. El coste de mantenimiento y la selección de qué automatizar pesan más que la discusión simplista entre manual y automatizado. La decisión útil es por riesgo: flujos repetibles y APIs estables suelen amortizarse; una UI cambiante y validaciones de UX suelen encajar mejor en manual o híbrido, como plantea este análisis sobre ROI en equipos pequeños.
Fase 1 Apagar incendios
Empieza por donde duele el negocio. No por donde resulta más elegante técnicamente.
Si el producto depende de activación, pagos, autenticación o permisos, automatiza una capa mínima de smoke tests y regresión sobre esos puntos. Pocos tests, pero ejecutados siempre. Aquí no buscas pureza arquitectónica. Buscas dejar de romper lo básico.
Checklist útil de esta fase:
- Identifica los flujos que impactan ingresos o retención
- Aísla APIs relativamente estables
- Monta ejecución automática en cada cambio relevante
- Elimina comprobaciones manuales repetitivas que consumen tiempo del equipo
Esta fase tiene que producir una sensación muy concreta. Menos sobresaltos tras desplegar.
Fase 2 Construir cimientos
Cuando ya no vives en modo reacción, mete el testing en el flujo de desarrollo real. Aquí la palanca no es añadir más E2E. Es introducir tests unitarios e integración como parte normal del trabajo de ingeniería.
El cambio importante en esta fase no es técnico, es cultural. Una feature no está terminada solo porque funciona en local. Está terminada cuando deja evidencia reproducible de que no rompe lo que toca.
Si el equipo escribe código nuevo sin decidir cómo lo va a verificar mañana, está posponiendo una deuda que pagará en cada release.
Prácticas que suelen funcionar:
- Definition of Done con tests mínimos esperados
- Pipeline de CI básico que bloquee errores evidentes
- Revisión de PR que valore testabilidad, no solo funcionalidad
- Refactor gradual de zonas imposibles de probar
Fase 3 Optimizar y escalar
Solo cuando las dos primeras capas funcionan tiene sentido ampliar ambición. Aquí ya puedes explorar performance, seguridad, datos de prueba más realistas y una integración más fina con CI/CD.
Esta fase también exige más disciplina para no inflar la suite. Cada test adicional debe justificar su coste de mantenimiento. Si una prueba falla por razones espurias, tarda demasiado o nadie la entiende, está erosionando confianza.
Qué sí compensa automatizar y qué no
Una guía corta y brutalmente honesta:
- Sí suele compensar
- Smoke tests de rutas críticas
- Regresión sobre negocio estable
- APIs con contratos claros
- Reglas de pricing, permisos y cálculo
- Interfaces que cambian cada sprint
- Flujos exploratorios
- Validaciones finas de UX
- Automatización montada solo para “dar imagen de madurez”
El roadmap bueno no intenta cubrir todo. Intenta reducir riesgo real con el menor coste sostenible.
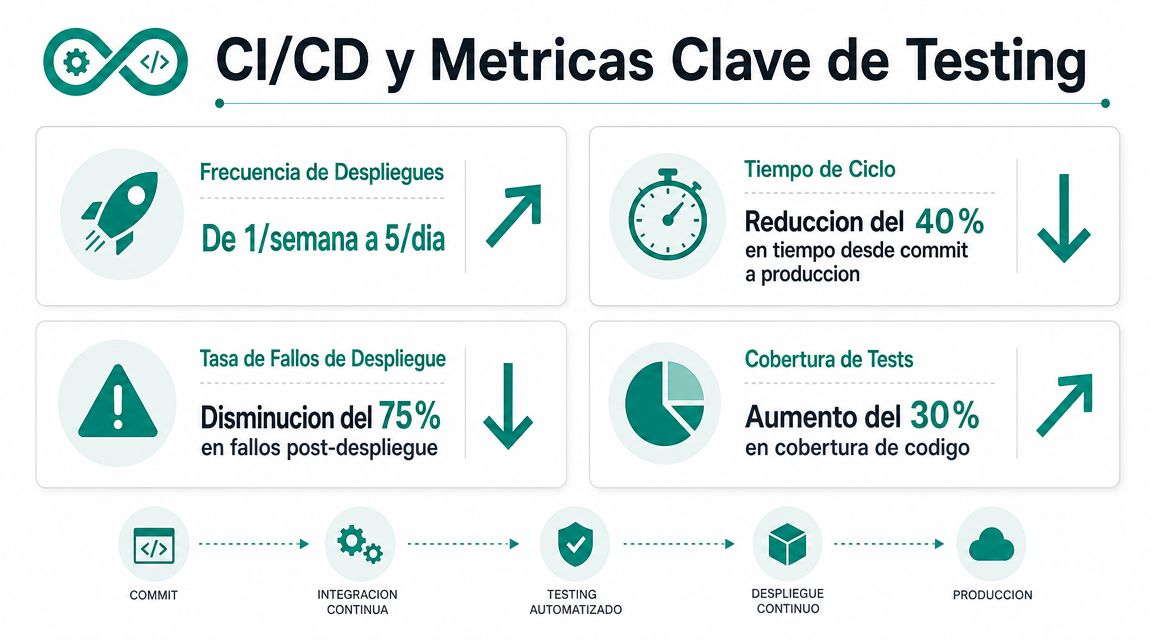
CI/CD y las métricas que de verdad importan
El testing automatizado cambia de verdad cuando entra en CI/CD. Mientras vive solo en el portátil de alguien, ayuda. Cuando se ejecuta de forma consistente dentro del pipeline, empieza a cambiar el comportamiento del equipo.
No se trata de “tener DevOps” como etiqueta. Se trata de acortar el tiempo entre cambio y feedback, y de reducir la incertidumbre antes de desplegar. Si quieres una visión más amplia del rol que sostiene ese sistema, esta guía explica qué hace un ingeniero DevOps en un equipo moderno.
Qué mirar y qué ignorar
Muchos equipos se obsesionan con métricas de vanidad. La más conocida es la cobertura de código como objetivo en sí mismo. Una cobertura alta puede convivir perfectamente con una suite inútil si los tests no protegen negocio ni detectan fallos relevantes.
Las métricas que sí cuentan una historia útil son otras:
- Flakiness. Si un test falla a veces sí y a veces no, está destruyendo confianza en la suite.
- Tiempo de ciclo. Cuánto tarda un cambio en pasar de commit a producción con seguridad razonable.
- Tiempo medio de recuperación. Cuando algo falla, cuánto tarda el equipo en entenderlo y corregirlo.
- Señal por fallo. Si un rojo en CI apunta claramente al problema o dispara una investigación caótica.
Lo que una buena suite le hace al equipo
Una suite bien integrada en CI/CD cambia decisiones del día a día:
- Los desarrolladores hacen cambios con menos miedo.
- Las revisiones de código se vuelven más concretas.
- El equipo detecta regresiones antes de que lleguen al cliente.
- El despliegue deja de ser un ritual tenso y pasa a ser una operación rutinaria.
Un pipeline útil no busca impresionar. Busca responder rápido a una pregunta simple: “¿es seguro seguir adelante?”
Si la suite tarda demasiado, falla sin motivo o genera falsos positivos, el equipo empezará a ignorarla. Ese es el punto de quiebre. En testing, la confianza del equipo importa tanto como la cobertura técnica.
Cómo contratar y evaluar perfiles de testing automatizado
Contratar bien aquí no consiste en encontrar a quien más herramientas enumera en el CV. Consiste en incorporar a alguien que sepa proteger velocidad de entrega sin convertir el testing en una deuda más. He visto equipos con una suite grande, cara y poco fiable. El problema no era la herramienta. Era el criterio con el que se diseñó.
La pregunta útil para un CTO o founder es otra: ¿necesitas a alguien que ejecute tests, a alguien que diseñe la estrategia, o a alguien que construya la base técnica para varios equipos?
Qué perfil estás buscando de verdad
Un QA Automation Engineer suele encajar mejor cuando el reto principal es definir cobertura, automatizar flujos relevantes y ordenar el proceso de calidad dentro del ciclo de entrega.
Un SDET o un perfil más cercano a software engineering aporta más valor si el cuello de botella está en la arquitectura de tests, la integración con CI, la mantenibilidad del framework o la necesidad de crear una plataforma de testing reutilizable.
No es la misma contratación en cada etapa de empresa.
- Startup en fase temprana. Conviene un perfil generalista, con criterio para priorizar riesgos y suficiente capacidad técnica para automatizar lo que más protege negocio sin sobrediseñar.
- Scaleup con varios squads. Suele compensar un perfil con más peso en arquitectura, estándares compartidos, observabilidad de la suite y soporte a múltiples equipos.
- Equipo muy apoyado en IA para desarrollar. Necesitas a alguien cómodo revisando código y tests generados por herramientas asistidas, porque la velocidad de producción de código ya no es el único cuello de botella. La validación pasa a ser parte central del trabajo.
Si necesitas contexto base sobre el rol, esta guía aclara qué es un QA tester y cómo encaja en equipos tech.
Qué señales separan experiencia real de familiaridad con herramientas
Playwright, Cypress, Selenium o Pytest se aprenden. Lo más difícil de encontrar es juicio técnico. Un buen candidato sabe explicar por qué automatizaría una cosa y dejaría otra fuera. También sabe decir que un flujo no merece un E2E si el riesgo se cubre mejor con tests de integración y un par de checks de contrato.
En entrevista, conviene llevar la conversación a decisiones concretas:
- Cuéntame un caso real de flakiness que hayas tenido que corregir.
Busca método. Si habla de sincronización, datos de prueba, aislamiento de entorno, dependencias externas y observabilidad del fallo, hay experiencia de verdad. - ¿Cómo decidirías qué automatizar en una feature nueva?
La respuesta buena suele mezclar impacto de negocio, frecuencia de uso, coste de mantenimiento y estabilidad esperada del flujo. - La suite E2E ya está frenando releases. ¿Qué harías en los próximos 30 días?
Un perfil maduro prioriza redistribuir cobertura, eliminar tests redundantes, atacar flaky tests y reducir tiempo de feedback. No propone solo más infraestructura. - ¿Cómo probarías una API crítica que cambia mucho?
Escucha si habla de contratos, versionado, datos sintéticos, mocks bien usados y límites de la automatización.
El ejercicio práctico que mejor predice rendimiento
Un ejercicio corto, parecido al trabajo real, da mucha más señal que una prueba algorítmica. Basta con una API pequeña o una UI sencilla con errores plausibles. Pide tres cosas: qué automatizaría primero, qué pruebas escribiría y qué dejaría fuera en esta fase.
Ahí aparece lo que luego importa en producción. Prioridad. Claridad. Calidad del código. Capacidad para explicar trade-offs sin refugiarse en teoría.
También sirve para detectar un problema habitual en contratación técnica en startups españolas. Hay candidatos que han mantenido tests. Hay menos candidatos que hayan tomado decisiones de inversión en testing con presión de roadmap, equipo pequeño y releases frecuentes. Ese segundo grupo es el que más valor aporta al principio.
IA generativa y nuevas señales de talento
La adopción de asistentes de IA ya está cambiando este rol. Flexygo lo describe en su análisis sobre testing automatizado, donde menciona usos como la generación de casos de prueba a partir de requisitos y el apoyo al mantenimiento de suites.
Eso no elimina la necesidad de buenos perfiles. La sube.
Ahora conviene evaluar cuatro capacidades adicionales:
- Revisar tests generados por IA con criterio técnico
- Convertir requisitos ambiguos en casos de prueba útiles
- Mantener trazabilidad entre requisito, test y riesgo cubierto
- Detectar tests correctos en sintaxis pero pobres en señal
El perfil fuerte ya no destaca solo por usar una herramienta concreta. Destaca por decidir bien qué probar, cómo integrarlo en el flujo del equipo y cómo usar IA sin degradar fiabilidad.
Si estás construyendo equipo y necesitas incorporar perfiles capaces de diseñar, ejecutar o liderar una estrategia de testing automatizado con criterio de negocio, en Kulturo trabajamos con startups y scaleups en España para contratar talento técnico con foco real en producto, calidad e IA.




