
06.06.2026
Event driven architecture: Guía para startups en España
Qué es el event driven architecture y cómo se implementa.
Pedro Cailá

Tu equipo ya ha pasado por esto. El checkout confirma un pedido, pero el stock tarda en reflejarse. El CRM se entera tarde. La notificación al cliente sale cuando ya no importa. Y cada nueva integración obliga a tocar el mismo monolito, cruzar dedos y bloquear a medio equipo durante el despliegue.
Ese punto de fricción no suele aparecer cuando tienes pocos clientes y un producto simple. Aparece cuando la startup ya vende, ya integra con terceros y ya tiene más de un flujo crítico compitiendo por prioridad. Ahí el patrón request-response empieza a enseñarte su límite. Todo depende de llamadas síncronas, dependencias frágiles y servicios que saben demasiado unos de otros.
La event driven architecture no arregla un mal producto ni sustituye una base de ingeniería sólida. Pero sí cambia algo decisivo: el sistema deja de pedir constantemente “¿ha pasado esto?” y empieza a reaccionar a “esto acaba de pasar”. Ese cambio reduce acoplamiento, acelera la evolución del producto y, bien ejecutado, te da una organización técnica mucho más modular.
Introducción por qué tu startup necesita reaccionar en lugar de pedir
Cuando una startup empieza a escalar, las dependencias síncronas entre servicios dejan de ser una decisión técnica cómoda y se convierten en un problema operativo. Cada petición entre sistemas añade latencia, puntos de fallo y coordinación entre equipos. El resultado no es solo un backend más frágil. Es una organización más lenta.
En una scaleup española esto se nota rápido. Producto quiere lanzar una nueva automatización comercial. Finanzas necesita que facturación cuadre en tiempo real. Soporte exige trazabilidad. Data pide eventos limpios para analítica. Si todo pasa por llamadas directas entre servicios, cada iniciativa relevante termina compitiendo por el mismo cuello de botella. Y eso castiga tanto la entrega como la contratación, porque acabas necesitando perfiles generalistas que apaguen fuegos en vez de equipos con fronteras claras y responsabilidad real sobre su dominio.
La arquitectura orientada a eventos corrige ese patrón. Un hecho de negocio ocurre y el sistema lo publica. A partir de ahí, los servicios que lo necesitan reaccionan sin bloquear el flujo principal. Si se confirma un pago, riesgo puede validarlo, operaciones puede preparar la entrega y customer success puede disparar una notificación. No hace falta encadenar llamadas ni coordinar releases en tres equipos para cada cambio de producto.
La señal de alerta es simple.
Regla práctica: si una funcionalidad nueva obliga a tocar varios servicios, alinear despliegues entre squads y negociar cambios de contrato interno para salir a producción, tienes demasiado acoplamiento.
EDA no arregla una mala modelización de dominio ni compensa un equipo débil. Sí te obliga a ordenar responsabilidades, definir eventos de negocio con criterio y contratar perfiles que entiendan integración, observabilidad y consistencia eventual. Para una startup que quiere crecer en España sin multiplicar el caos técnico, esa combinación importa mucho más que adoptar la tecnología de moda.
Si operas con microservicios, procesos transaccionales, integraciones con terceros o cargas que cambian por campañas, partners o estacionalidad, seguir pidiendo de forma síncrona te va a salir caro. En incidencias, en velocidad de entrega y en estructura de equipo. Reaccionar a eventos no es un capricho arquitectónico. Es una forma más seria de construir producto y de escalar talento sin convertir cada release en una negociación entre dependencias.
Qué es una arquitectura orientada a eventos
Piensa en una agencia de noticias. Cuando ocurre algo relevante, un redactor envía la noticia. La agencia la recibe y la distribuye. Luego cada medio decide si la publica, la analiza o la ignora. El redactor no necesita llamar uno por uno a todos los periódicos. Solo emite el hecho.
Eso es una arquitectura orientada a eventos. Un servicio produce un evento. Un intermediario lo enruta. Uno o varios consumidores reaccionan. El productor no necesita saber quién consume ni cuándo lo hará. Esa separación es el beneficio central.
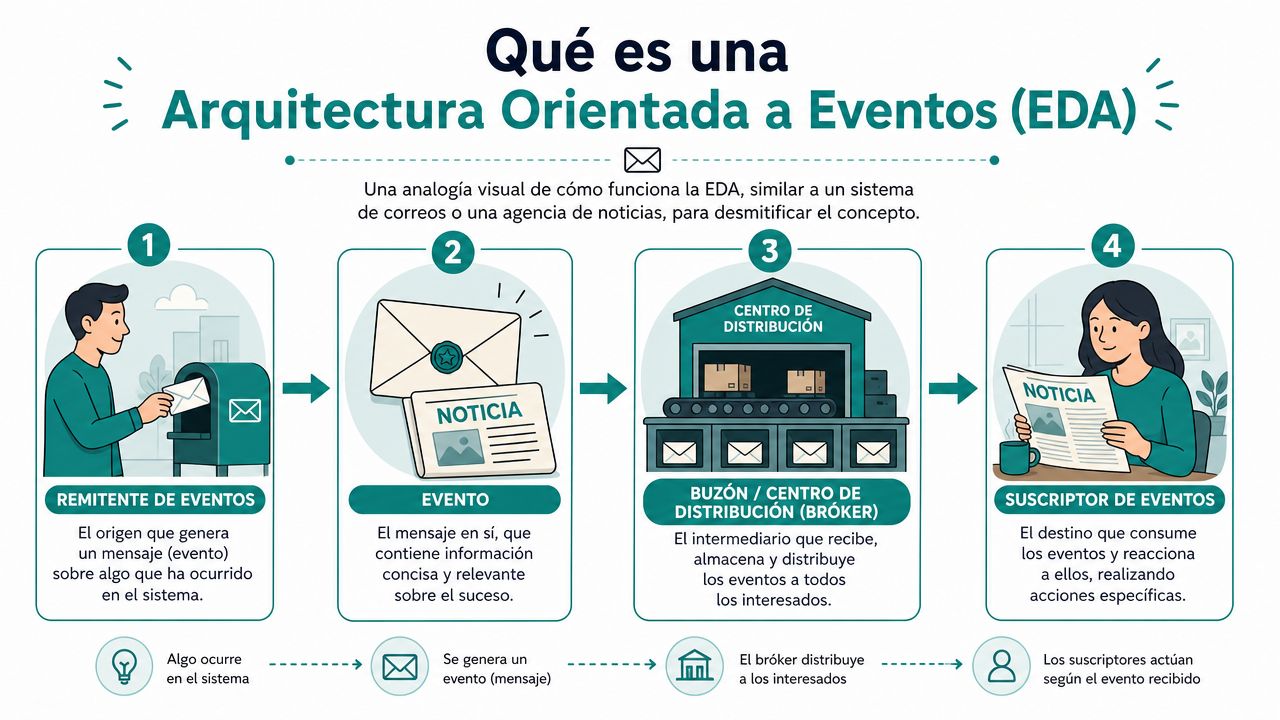
Los tres componentes que importan
AWS lo deja bastante claro: su arquitectura se apoya en tres componentes, productores, routers y consumidores, y remarca que los servicios quedan desacoplados, lo que permite escalarlos, actualizarlos y desplegarlos de forma independiente en su guía sobre event-driven architecture.
Llevado a producto real:
- Productores. Son los servicios que detectan un hecho de negocio y publican un evento. Un pago aprobado, una suscripción cancelada, una incidencia abierta.
- Routers o brókers. Son el centro de distribución. Reciben eventos y los entregan a quien corresponda. Aquí viven productos como Apache Kafka, RabbitMQ o Amazon EventBridge.
- Consumidores. Son los servicios que reaccionan. Pueden ejecutar una tarea operativa, persistir datos, enriquecer contexto o lanzar procesos posteriores.
La ventaja no está en “mandar mensajes”. La ventaja está en que cada servicio puede evolucionar sin depender del conocimiento interno de los demás. Esa propiedad cambia cómo diseñas equipos, ownership y releases.
Lo que cambia frente al modelo clásico
En request-response, un servicio pide algo a otro y espera respuesta. Eso encaja bien en operaciones inmediatas y simples. Pero se vuelve caro cuando varios subsistemas necesitan procesar el mismo hecho, cuando exiges baja latencia o cuando quieres detectar patrones dentro de una ventana temporal.
Microsoft añade precisamente que los eventos se entregan en casi tiempo real y que este patrón es especialmente útil en esos escenarios. IBM, además, distingue entre simple event processing, event stream processing y complex event processing, una clasificación útil para separar automatizaciones básicas de analítica más sofisticada.
Para aterrizarlo, este vídeo resume bien la idea antes de entrar en decisiones de diseño:
Un buen evento describe algo que ya ha ocurrido. No una orden disfrazada. Si publicas enviar_email_bienvenida, estás acoplando. Si publicas usuario_registrado, estás diseñando mejor.
Qué no es EDA
No es “poner Kafka y ya”. Tampoco es convertir cualquier CRUD en un festival de eventos. Si tu dominio no necesita reacción asíncrona, múltiples consumidores o independencia operativa, puedes acabar metiendo complejidad donde no hacía falta.
EDA funciona especialmente bien cuando los hechos de negocio son importantes por sí mismos. Si tu sistema gira alrededor de esos hechos, el modelo encaja. Si no, probablemente estés forzando la arquitectura.
Patrones clave de arquitectura orientada a eventos
No todos los patrones de EDA valen para una startup en crecimiento. Hay tres que sí aparecen una y otra vez cuando el producto empieza a complicarse: Publish/Subscribe, Event Sourcing y Stream Processing. No los metas todos a la vez. Elige el que resuelve tu cuello de botella actual.
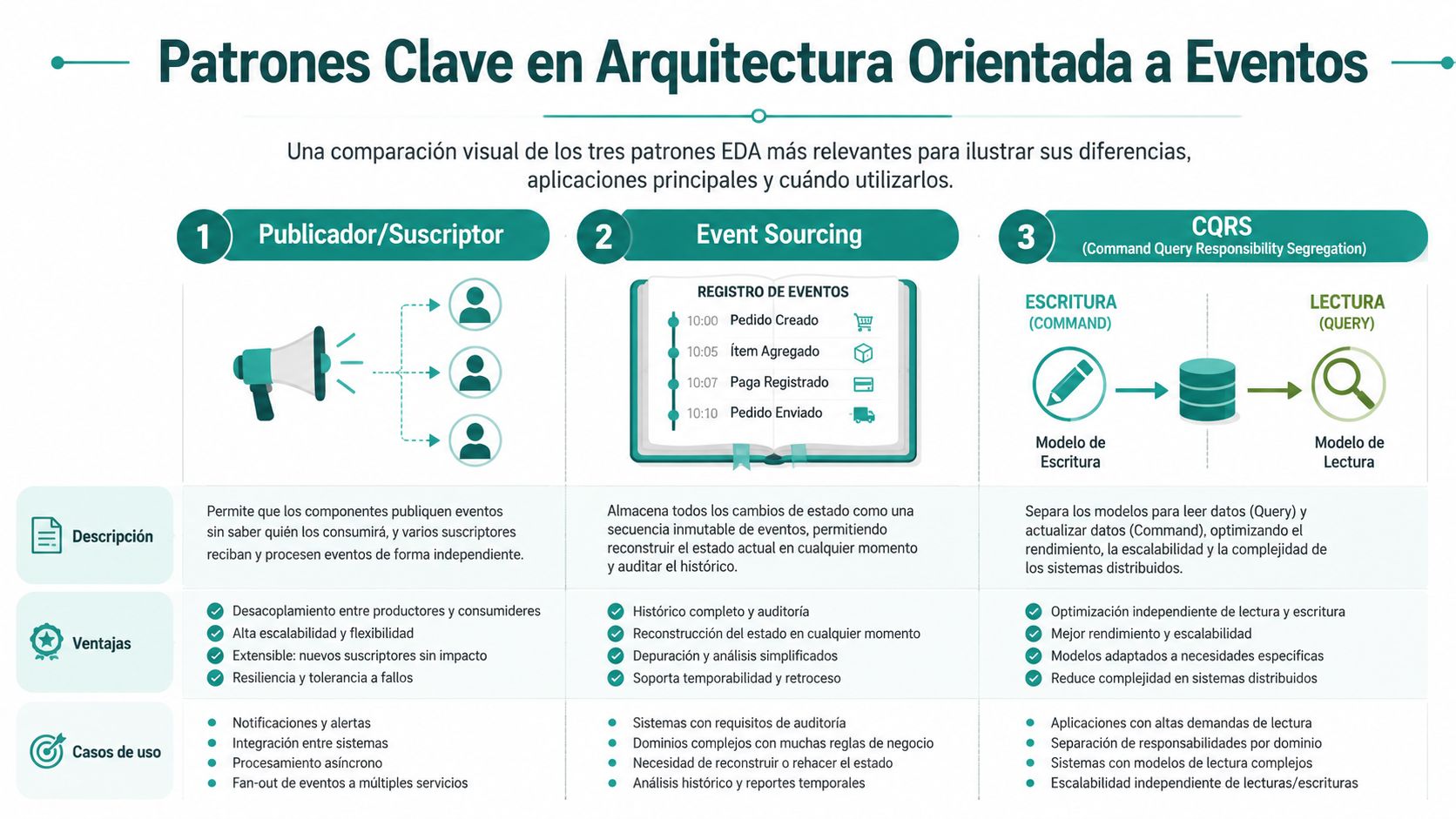
Publish subscribe
Es el patrón por defecto. Un servicio publica un evento y varios consumidores lo reciben de forma independiente.
Usa esto cuando...
- Necesitas desacoplar integraciones. Tu servicio de pedidos no debería conocer ni el servicio de emails, ni el de fidelización, ni el de analítica.
- Quieres añadir capacidades sin tocar el core. Si mañana lanzas un motor de recomendaciones, te suscribes a eventos existentes y avanzas sin reescribir medio backend.
- Tienes equipos distintos por dominio. Cada squad consume lo que necesita y mantiene su lógica.
Cuidado con...
- Eventos mal nombrados. Si publicas eventos técnicos en vez de eventos de negocio, creas ruido y dependencia accidental.
- Explosión de suscriptores invisibles. Sin catálogo ni gobierno, nadie sabe quién depende de qué.
- Reprocesado confuso. Si un consumidor falla, necesitas reglas claras de reintento e idempotencia.
Event sourcing
Aquí no guardas solo el estado actual. Guardas la secuencia de eventos que llevó a ese estado. Luego reconstruyes la entidad cuando hace falta.
Esto tiene mucho sentido en dominios donde importa saber qué pasó y en qué orden. Fintech, facturación, pricing, auditoría interna, operaciones sensibles.
Usa esto cuando...
- La trazabilidad no es negociable. Quieres reconstruir por qué una orden terminó en un estado concreto.
- El histórico tiene valor operativo. No solo legal. También para soporte, conciliación o análisis de comportamiento.
- El dominio cambia con frecuencia. Tener eventos persistidos te da flexibilidad para proyectar nuevas vistas sin rehacer toda la historia.
Cuidado con...
- Complejidad cognitiva. Tu equipo tiene que entender snapshots, proyecciones, versionado de eventos y reconstrucción de estado.
- Lecturas más difíciles. Consultar el estado actual puede requerir modelos derivados.
- Mala disciplina de diseño. Si los eventos no están bien definidos, tu histórico se vuelve una carga, no un activo.
Si todavía estás discutiendo nombres de entidades básicas y ownership entre equipos, no empieces por Event Sourcing. Empieza por Pub/Sub bien hecho.
Stream processing
Aquí no trabajas con eventos aislados, sino con flujos continuos. Lo útil no es un evento en sí, sino el patrón que emerge del conjunto.
En producto se ve mucho en scoring, detección de anomalías, analítica operativa o sistemas IoT. Si necesitas entender secuencias, ventanas temporales o agregaciones en tiempo casi real, este patrón encaja. Si quieres profundizar en esa capa de procesamiento de datos, conviene conectar esta discusión con cómo funciona el big data en sistemas modernos.
Usa esto cuando...
- Necesitas reaccionar sobre el flujo. No basta con saber que ocurrió un evento. Necesitas detectar tendencia, umbral o secuencia.
- Trabajas con señales continuas. Telemetría, actividad de usuario, sensores o eventos de plataforma.
- El valor baja con el tiempo. Si analizar dentro de unos minutos ya no sirve, necesitas procesamiento continuo.
Cuidado con...
- Operación más exigente. Frameworks como Apache Flink o Spark Structured Streaming no son un hobby de viernes.
- Depuración compleja. Los errores en ventanas, orden o tiempo de evento son difíciles de rastrear.
- Contratación más dura. Encontrar ingenieros que dominen streaming de verdad cuesta más que encontrar backend generalista.
Ventajas estratégicas y desafíos reales
Tu startup lo nota en cuanto crece un poco. Un pago confirmado dispara stock, facturación, email, antifraude, analytics y soporte. Si todo eso sigue encadenado por llamadas síncronas, cada nuevo flujo mete más acoplamiento, más esperas y más puntos de fallo. La arquitectura orientada a eventos empieza a tener sentido justo ahí. No por moda, sino porque deja de penalizar cada cambio de producto con una negociación entre cinco equipos.
La ventaja principal es simple: separas capacidades sin frenar el negocio. Catálogo, pagos, notificaciones o riesgo pueden evolucionar a ritmos distintos y escalar de forma independiente. Para una scaleup española esto importa mucho. Sueles tener un equipo backend todavía pequeño, presión comercial para lanzar integraciones rápido y poca tolerancia a incidentes fuera de horario.
Lo que ganas si lo haces bien
La primera ganancia es velocidad de ejecución. Un equipo puede publicar un evento estable y otro construir encima sin abrir una cadena eterna de dependencias. Eso reduce reuniones de coordinación, baja el coste de cambiar prioridades y acelera el onboarding de nuevos ingenieros.
La segunda es resiliencia operativa. Si falla un consumidor secundario, el flujo principal puede seguir vivo. En ecommerce, por ejemplo, un problema en recomendaciones no debería bloquear la confirmación de compra. En una fintech, un retraso en analítica no puede frenar la recepción de una transacción.
La tercera es mejor diseño organizativo. EDA obliga a aclarar ownership. ¿Quién publica pedido_pagado? ¿Qué contrato mantiene? ¿Qué consumidor puede romper si cambia el esquema? Esa disciplina mejora la arquitectura y también la estructura del equipo. Si nadie sabe de quién es un evento, tampoco sabes a quién contratar ni qué perfil promocionar a tech lead.
Lo que pagas de verdad
Pagas complejidad distribuida. El error ya no vive en una request y un stack trace. Vive en reintentos, duplicados, orden parcial, consumidores lentos y estados intermedios. Si tu equipo todavía depura todo mirando logs sueltos, vas tarde.
Pagas consistencia eventual. Producto, operaciones y atención al cliente tienen que entender qué datos son inmediatos y cuáles tardan segundos o minutos en propagarse. Si esa conversación no ocurre pronto, acabarás discutiendo incidentes que en realidad son decisiones de diseño mal explicadas.
Pagas observabilidad desde el primer día. Correlation IDs, tracing, métricas por consumer group, dead letter queues visibles y dashboards por flujo de negocio. Sin eso, el sistema funciona hasta que deja de hacerlo. Y cuando falla, el coste no es solo técnico. Tu equipo de guardia pierde horas, producto pierde confianza y la dirección empieza a ver la plataforma como un freno.
Mi recomendación: no montes EDA si no puedes asignar ownership claro por evento, versionar contratos y medir el estado de cada flujo importante desde el primer sprint.
Un trade-off frecuentemente ignorado
EDA cambia el tipo de equipo que necesitas. No basta con buenos backend generalistas. Necesitas ingenieros que entiendan idempotencia, semántica de entrega, particionado, evolución de esquemas y consumo seguro de eventos. Ese talento no sobra en España, y menos en startups que compiten con remoto internacional y con bancos, consultoras o grandes tecnológicas por los mismos perfiles.
Aquí está una de las decisiones más prácticas del artículo. Si tu empresa aún no tiene ese nivel de madurez, no intentes resolverlo contratando solo seniors caros al final del proceso. Define antes qué parte del problema quieres dominar dentro de casa. Si tu ventaja competitiva está en el flujo de negocio, contrata platform engineers o backend engineers con experiencia real en mensajería y contratos. Si el caso de uso exige streaming serio, asume un proceso de hiring más lento, salarios más altos y una curva de onboarding más exigente.
En una scaleup, la mala decisión no es elegir RabbitMQ, Kafka o Pub/Sub. La mala decisión es implantar una arquitectura que tu equipo no puede operar ni explicar. Ahí es donde EDA deja de ser una ventaja estratégica y se convierte en deuda organizativa.
Casos de uso reales para startups en España
En España, la conversación sobre EDA deja de ser académica muy rápido. Basta con tocar ecommerce, fintech, SaaS B2B o plataformas con integración contable para ver por qué el patrón encaja.
Un ejemplo simple es ecommerce. En cuanto un cliente paga, no quieres una llamada en cadena donde pedido, stock, notificación, antifraude y analítica dependan unos de otros en tiempo de respuesta. Quieres publicar pedido_pagado y dejar que cada capacidad actúe por separado. Si falla el módulo promocional, no debería bloquear el flujo principal.
Cuando negocio ya funciona como una secuencia de hechos
En fintech pasa algo parecido. Un ingreso, una validación KYC, una conciliación o un cambio de estado regulatorio no son solo operaciones. Son hechos de negocio que distintos subsistemas deben registrar, enriquecer o supervisar.
IoT también encaja de forma natural. Sensores, dispositivos o telemetría generan eventos continuos. Ahí no tiene sentido diseñar un sistema que viva preguntando si algo ha pasado. Tiene más sentido que procese lo que va ocurriendo y reaccione por prioridad.
- Ecommerce. Pedido creado, pago confirmado, stock reservado, expedición iniciada.
- Fintech. Transacción recibida, validación ejecutada, alerta generada, cuenta actualizada.
- SaaS B2B. Usuario activado, licencia cambiada, factura emitida, integración sincronizada.
- IoT. Señal recibida, umbral superado, alerta operativa, acción automatizada.
El factor español que muchos subestiman
En el mercado español hay un acelerador adicional: la regulación. La Ley 18/2022 impulsa la factura electrónica en relaciones entre empresas y autónomos, lo que empuja a diseñar flujos asíncronos y auditables. Además, el marco del Suministro Inmediato de Información (SII) de la AEAT exige la remisión casi en tiempo real de registros de facturación, un escenario donde EDA reduce el acoplamiento y mejora la trazabilidad tal y como se resume en esta referencia sobre factura electrónica y SII.
Eso tiene consecuencias de diseño muy concretas. Si trabajas con ERP, CRM, validación documental y sistemas fiscales, necesitas tratar cada cambio de estado como un evento procesable. No puedes depender de un flujo lineal frágil donde cualquier caída rompa el circuito completo.
Lo que yo haría en una scaleup española
Separaría claramente estos flujos:
- Eventos de negocio como factura emitida, cobro conciliado o pedido completado.
- Consumidores regulados que persisten, validan y mantienen trazabilidad.
- Reintentos idempotentes para no duplicar operaciones sensibles.
- Persistencia en el broker para absorber indisponibilidades temporales de consumidores.
Aquí EDA no es “una arquitectura bonita”. Es una manera realista de operar con integraciones, obligaciones regulatorias y crecimiento de producto sin convertir cada cambio en una intervención de alto riesgo.
Pila tecnológica y decisiones críticas de diseño
El error habitual es empezar por la herramienta. Kafka, RabbitMQ, Amazon EventBridge, Google Cloud Pub/Sub, AWS Kinesis. Todo eso importa, pero menos de lo que parece. Primero decide qué problema operativo y organizativo necesitas resolver.
Si tu prioridad es mensajería fiable entre servicios con rutas relativamente claras, una cola de mensajes puede bastar. Si necesitas retención, relectura y una plataforma preparada para flujos de alto volumen, el streaming encaja mejor. Si tu equipo es pequeño y no quieres operar infraestructura compleja, los servicios gestionados en cloud suelen ser la decisión sensata.
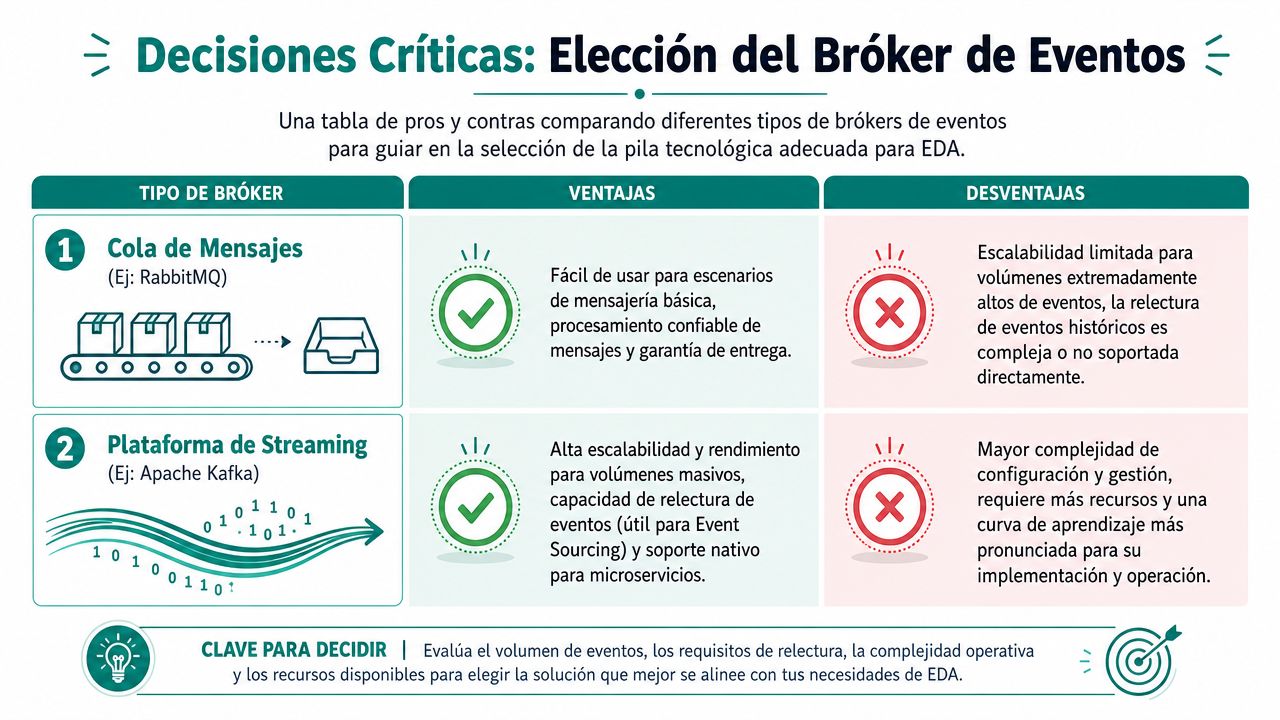
Cómo elegir el broker sin perder seis semanas
Yo uso un criterio simple:
- RabbitMQ cuando el caso principal es colas, routing flexible y procesamiento de mensajes relativamente tradicional.
- Apache Kafka cuando el evento es un activo persistente, quiero replay y varios consumidores con ritmos distintos.
- Servicios cloud como Amazon Kinesis, Amazon EventBridge o Google Cloud Pub/Sub cuando priorizo velocidad de implantación y menos carga operativa.
La decisión no es solo técnica. También depende del equipo que tengas disponible para operar la plataforma. Si no cuentas con experiencia real en sistemas distribuidos y observabilidad, montar Kafka autogestionado demasiado pronto puede ser una mala idea. Si estás valorando esa capacidad operativa, esta guía sobre qué hace un ingeniero DevOps en equipos modernos ayuda a separar responsabilidades reales de expectativas infladas.
El contrato del evento importa más que el broker
He visto equipos discutir semanas sobre infraestructura y luego publicar eventos mal versionados con payloads inconsistentes. Eso sí rompe proyectos.
Define un esquema desde el principio. Avro y Protobuf son opciones razonables si quieres control de evolución y compatibilidad. JSON puede servir al inicio, pero sin disciplina de versionado se degrada rápido. La regla es simple: un evento es un contrato entre equipos, no un detalle de implementación.
Publica eventos pequeños, estables y orientados a negocio. Si tu payload parece una copia de una tabla o una respuesta REST reciclada, vas mal.
Fallos, reintentos y mensajes muertos
La resiliencia no sale gratis. Tienes que diseñarla.
Haz esto desde el primer día:
- Implementa idempotencia en consumidores críticos. Un mismo evento puede llegar más de una vez.
- Aplica reintentos con backoff. Reintentar en bucle rápido solo multiplica el problema.
- Usa Dead-Letter Queues o mecanismos equivalentes. Si un mensaje no se puede procesar, necesitas aislarlo y analizarlo.
- Añade correlación. Cada evento debe permitir rastrear el flujo completo entre productores y consumidores.
Dos decisiones que afectan a la estructura del equipo
La primera es si la plataforma de eventos será responsabilidad de un equipo central o una capacidad compartida entre squads. En una scaleup, suelo preferir un equipo plataforma pequeño que defina estándares, observabilidad y gobierno, sin secuestrar la autonomía de producto.
La segunda es el modelo de ownership del esquema. Cada evento necesita un dueño claro. Si nadie decide cuándo cambia, cómo se versiona y quién comunica el impacto, el sistema se degrada muy deprisa.
Checklist para contratar tu equipo de EDA
La mayoría de los problemas de EDA no vienen de la teoría. Vienen de contratar backend generalista para un problema de sistemas distribuidos. Si quieres que esto funcione, necesitas gente que haya peleado con orden de eventos, retries, latencia, contratos y trazabilidad. No basta con alguien que “ha usado Kafka un poco”.

Los perfiles que sí contrataría
Para una scaleup, el núcleo suele ser este:
- Backend senior con experiencia en sistemas distribuidos. Debe dominar diseño de consumidores, idempotencia, manejo de errores y contratos de eventos.
- Arquitecto o staff engineer con criterio de integración. No para hacer diagramas bonitos, sino para fijar límites de dominio, gobierno de eventos y decisiones de evolución.
- Especialista en plataforma o DevOps/Cloud. Necesario si operas brokers, observabilidad y seguridad de la plataforma.
- Data engineer o perfil de streaming cuando el valor está en procesar flujos, no solo en mover mensajes.
Si quieres precisar mejor el nivel de seniority y alcance esperado de ese rol transversal, vale la pena revisar qué diferencia de verdad a un arquitecto de software en equipos que escalan.
Habilidades no negociables
No pongas una lista infinita. Evalúa estas capacidades de verdad:
- Diseño de eventos. El candidato debe distinguir entre evento de negocio, comando y notificación técnica.
- Semántica de entrega. Tiene que saber qué implica recibir duplicados, desorden o retrasos.
- Observabilidad distribuida. Logs sin correlación no sirven. Debe hablar de tracing, métricas de consumo y diagnóstico de flujos.
- Evolución de contratos. Necesitas experiencia con versionado y compatibilidad hacia atrás.
- Recuperación operativa. Reintentos, DLQ, replay y procedimientos de incidencias.
Preguntas de entrevista que separan teoría de experiencia
Haz preguntas situacionales. Las respuestas vagas se notan enseguida.
- “Tienes un consumidor que procesa pagos confirmados y a veces recibe el mismo evento más de una vez. ¿Cómo implementas idempotencia sin perder throughput?”
Aquí quieres oír claves de deduplicación, claves de negocio, persistencia del estado procesado y trade-offs. - “Un evento cambia de esquema y rompe un consumidor antiguo. ¿Cómo habrías diseñado el versionado para evitarlo?”
Si la persona no habla de compatibilidad, ownership y evolución progresiva, aún no ha sufrido suficiente. - “Producción muestra retraso en un flujo crítico, pero el productor va bien. ¿Qué miras primero?”
Una buena respuesta recorre broker, particiones o colas, lag, throughput, errores de consumidores y observabilidad end-to-end. - “¿Cuándo no usarías Event Sourcing aunque la trazabilidad importe?”
Esto revela madurez. Quieres alguien que entienda el coste operativo y no venda complejidad como virtud.
Filtro útil: si un candidato responde todo con definiciones de libro y ninguna cicatriz operativa, no es el perfil para liderar EDA.
Cómo organizar el equipo para no crear otro cuello de botella
No metas toda la responsabilidad en una “guild” abstracta. Tampoco dejes libertad total desde el primer día.
Yo haría esto:
- Equipo plataforma pequeño. Define herramientas, librerías comunes, observabilidad y estándares.
- Squads dueños de eventos de su dominio. Publican, versionan y mantienen sus contratos.
- Revisión técnica ligera para nuevos eventos críticos. No para frenar, sí para evitar caos.
- Runbooks y ownership operativo. Cada flujo relevante debe tener responsables claros en incidencias.
Señales rojas al contratar
Evita perfiles que:
- Hablan solo de microservicios pero no de datos y consistencia.
- Conocen el broker pero no el modelo de dominio.
- Reducen EDA a “mensajería asíncrona” sin hablar de contratos ni observabilidad.
- Nunca han operado sistemas con fallos reales y no saben explicar cómo depurarlos.
La contratación en EDA no va de coleccionar keywords. Va de encontrar gente capaz de tomar decisiones bajo ambigüedad técnica y operativa.
Conclusión una inversión en agilidad y talento
La event driven architecture no es una capa moderna que añades encima de un sistema tenso para sentir que avanzas. Es una decisión estructural. Cambia cómo modelas el negocio, cómo separas equipos, cómo despliegas, cómo depuras y cómo contratas.
Si tu startup ya opera con múltiples integraciones, flujos sensibles al tiempo, requisitos de trazabilidad o presión por escalar sin romper el core, este enfoque tiene sentido. Pero solo funciona cuando la arquitectura y el talento avanzan juntos.
Mi opinión es simple. Empieza por flujos de negocio claros, no por una reescritura total. Define eventos con disciplina. Invierte pronto en observabilidad. Y contrata a gente que entienda sistemas distribuidos de verdad. Ahí está la ventaja competitiva. No en el broker. En la capacidad del equipo para convertir eventos en producto, operación y velocidad.
Si estás montando o reforzando un equipo para llevar esta transición sin improvisar, Kulturo ayuda a startups y scaleups en España a contratar perfiles técnicos con criterio real en backend, data, cloud, DevOps y arquitectura.




