
12.06.2026
Knowledge transfer: guía práctica para equipos tech
Qué es knowledge transfer. Cómo se debe gestionar el conocimiento en un equipo tech?
Pedro Cailá

Te avisa un senior de backend que se va en tres semanas. No es solo un buen ingeniero. Es la persona que montó la arquitectura de microservicios, conoce los atajos peligrosos, recuerda por qué se descartó aquella cola de mensajes y sabe qué servicio se rompe cuando sube cierta carga. En Jira no está ese contexto. En el código, solo una parte. En su cabeza, casi todo.
Ese momento provoca un tipo de pánico muy concreto. No es un problema administrativo. Es un riesgo técnico, operativo y de negocio. Si el conocimiento crítico vive en dos o tres personas, tu startup no está escalando. Está acumulando deuda invisible.
He visto este patrón muchas veces. Equipos que creen que hacen knowledge transfer porque tienen un Notion enorme, una carpeta en Drive y una sesión de handover al final. Luego entra alguien nuevo, tarda semanas en entender qué importa de verdad y vuelve a abrir debates ya resueltos. El problema no era la falta de documentos. Era la ausencia de un sistema útil para capturar conocimiento tácito, ponerlo en circulación y mantenerlo vivo.
La transferencia de conocimiento bien hecha no consiste en documentarlo todo. Consiste en decidir qué conocimiento es crítico, quién debe tenerlo, cómo se transfiere y cómo compruebas que se puede aplicar. Esa diferencia separa a los equipos que escalan de los que dependen de héroes.
También tiene un componente cultural. Si la empresa premia al que “salva” incidentes pero no al que deja contexto reutilizable, estás construyendo fragilidad. Por eso el knowledge transfer está mucho más cerca de la ejecución diaria y de la cultura empresarial de lo que muchos founders creen.
Introducción
Cuando una startup empieza a crecer, el conocimiento se concentra. Al principio parece eficiente. Una persona lleva infra, otra datos, otra billing, otra el pipeline de despliegue. Todo va rápido porque no hay que coordinar demasiado. El coste aparece después, cuando alguien se va, cambia de rol o simplemente deja de tocar un área durante meses.
El peor error es tratar ese riesgo como una excepción. No lo es. En equipos pequeños y medianos, la pérdida de contexto técnico pasa antes o después. Y cuando pasa, no se pierde solo información. Se pierde criterio. Se pierde el porqué de decisiones que hoy parecen raras pero que quizá evitaron un problema serio hace un año.
La mayoría de fallos de knowledge transfer no vienen de no tener documentación. Vienen de confundir documentación con entendimiento.
En una startup, necesitas un sistema que funcione con poco tiempo, con prioridades cambiantes y con equipos que no pueden dedicar media semana a procesos. Eso obliga a ser selectivo. Hay que capturar lo que rompe onboarding, lo que bloquea incidentes, lo que afecta a arquitectura y lo que condiciona roadmap.
Por eso esta guía evita la versión corporativa del problema. No vas a encontrar un programa pesado de governance ni ceremonias vacías. Vas a encontrar un enfoque práctico para que el conocimiento crítico no dependa de memoria individual, buena voluntad o heroicidades de última hora.
Por qué tu startup no puede ignorar el knowledge transfer
Muchas startups tratan el knowledge transfer como una tarea reactiva. Se activa cuando alguien se va. Eso llega tarde. Si el conocimiento ya estaba encerrado en una sola persona, el daño ya estaba hecho.
La transferencia efectiva de conocimiento sí tiene impacto operativo. En organizaciones técnicas, mejora la productividad en torno a un 25% y reduce la rotación de empleados en un 35%, según la guía de ASME sobre transferencia de conocimiento. No hace falta adornarlo. Si produces más y retienes mejor, estás ganando velocidad y estabilidad a la vez.
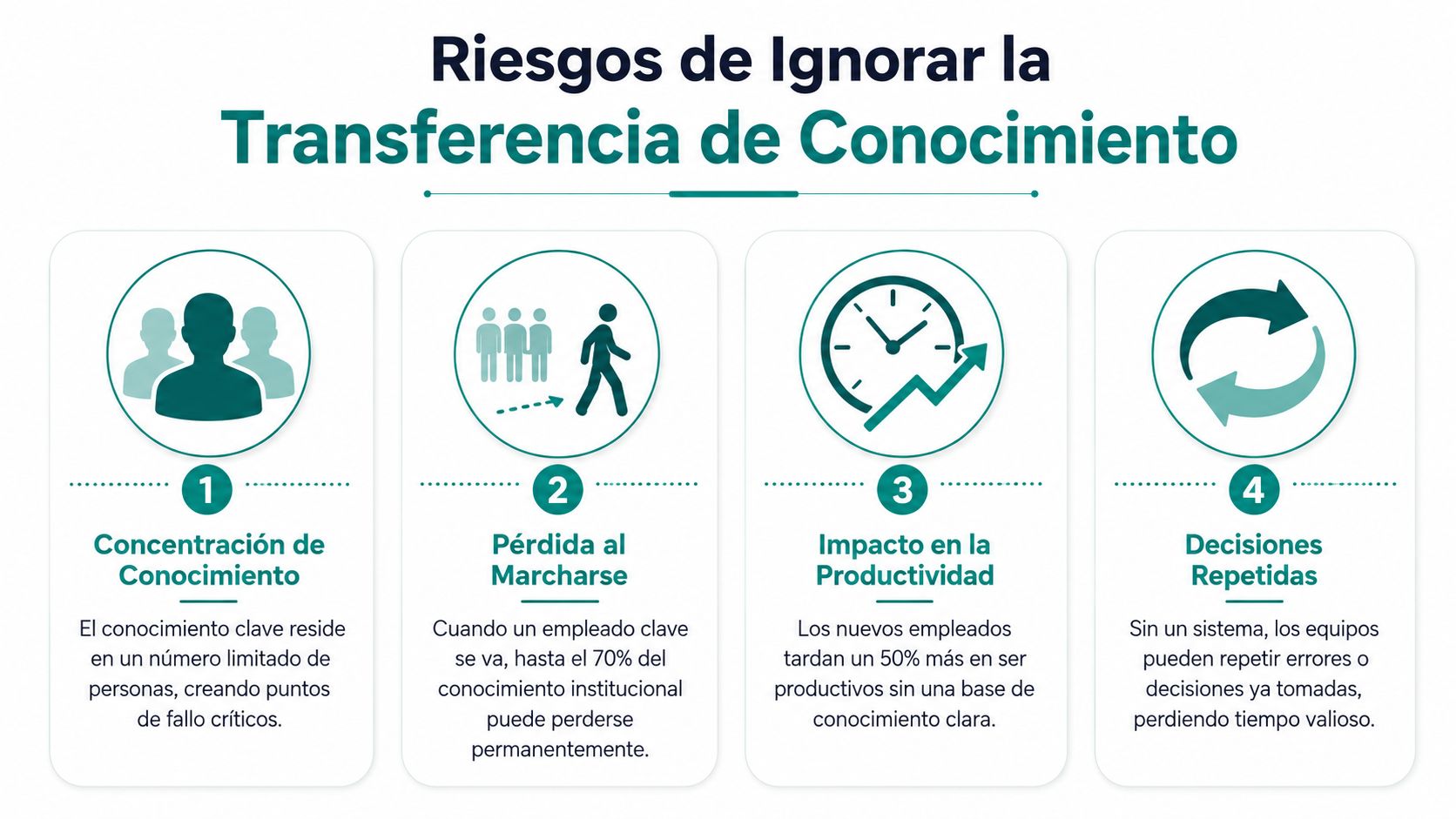
Lo que realmente estás arriesgando
En una startup, casi ningún problema de conocimiento aparece como “problema de conocimiento”. Aparece como otra cosa:
- Onboarding lento. La persona nueva tarda demasiado en entender qué servicios son críticos, qué decisiones no deben tocarse y dónde están los puntos frágiles.
- Decisiones repetidas. El equipo vuelve a discutir alternativas descartadas porque nadie dejó el contexto.
- Incidentes más caros. Cuando falla producción, no basta con tener runbooks. Hace falta entender comportamientos, dependencias y excepciones.
- Dependencia de individuos. Si siempre hay una persona a la que todo el mundo pregunta, tu sistema no escala.
Lo importante aquí es el coste compuesto. Una sola laguna de conocimiento no hunde una startup. Diez lagunas repartidas entre backend, datos, producto y operaciones sí.
Lo que sí cambia cuando lo haces bien
Un sistema razonable de knowledge transfer no convierte a todo el mundo en experto en todo. Tampoco debería intentarlo. Lo que hace es bajar el riesgo de forma clara: más personas entienden las piezas críticas, el contexto se preserva y las incorporaciones nuevas encuentran antes su sitio.
Regla práctica: si una decisión técnica importante no puede explicarse en cinco minutos con apoyo de artefactos concretos, esa decisión no está suficientemente transferida.
También mejora la calidad de colaboración. Cuando los equipos comparten contexto, dejan de pelear por malentendidos básicos. Backend entiende mejor los límites de datos. Data sabe qué contratos de eventos son frágiles. DevOps no descubre tarde dependencias no documentadas.
Ignorarlo sale caro porque obliga a reconstruir una y otra vez el mismo conocimiento. Y reconstruir conocimiento bajo presión siempre cuesta más que transferirlo con calma.
Diseñando tu programa de transferencia de conocimiento
Un programa de knowledge transfer útil en una startup se sostiene sobre tres pilares. Onboarding, offboarding y conocimiento continuo. Si te falta uno, el sistema cojea. Si solo haces offboarding, llegas tarde. Si solo haces onboarding, dependes de que nada cambie. Si solo haces sesiones internas, acumulas contexto sin estructura.
Un análisis de 79 artículos identificó seis componentes clave para que la transferencia funcione: mensaje, stakeholders, proceso, contexto interno, contexto sociocultural-económico y evaluación, como recoge la revisión académica publicada en PMC. Traducido al día a día de una startup, significa algo muy simple: no basta con pasar información. Importa qué transfieres, entre quiénes, en qué momento, en qué entorno y cómo verificas que ha servido.
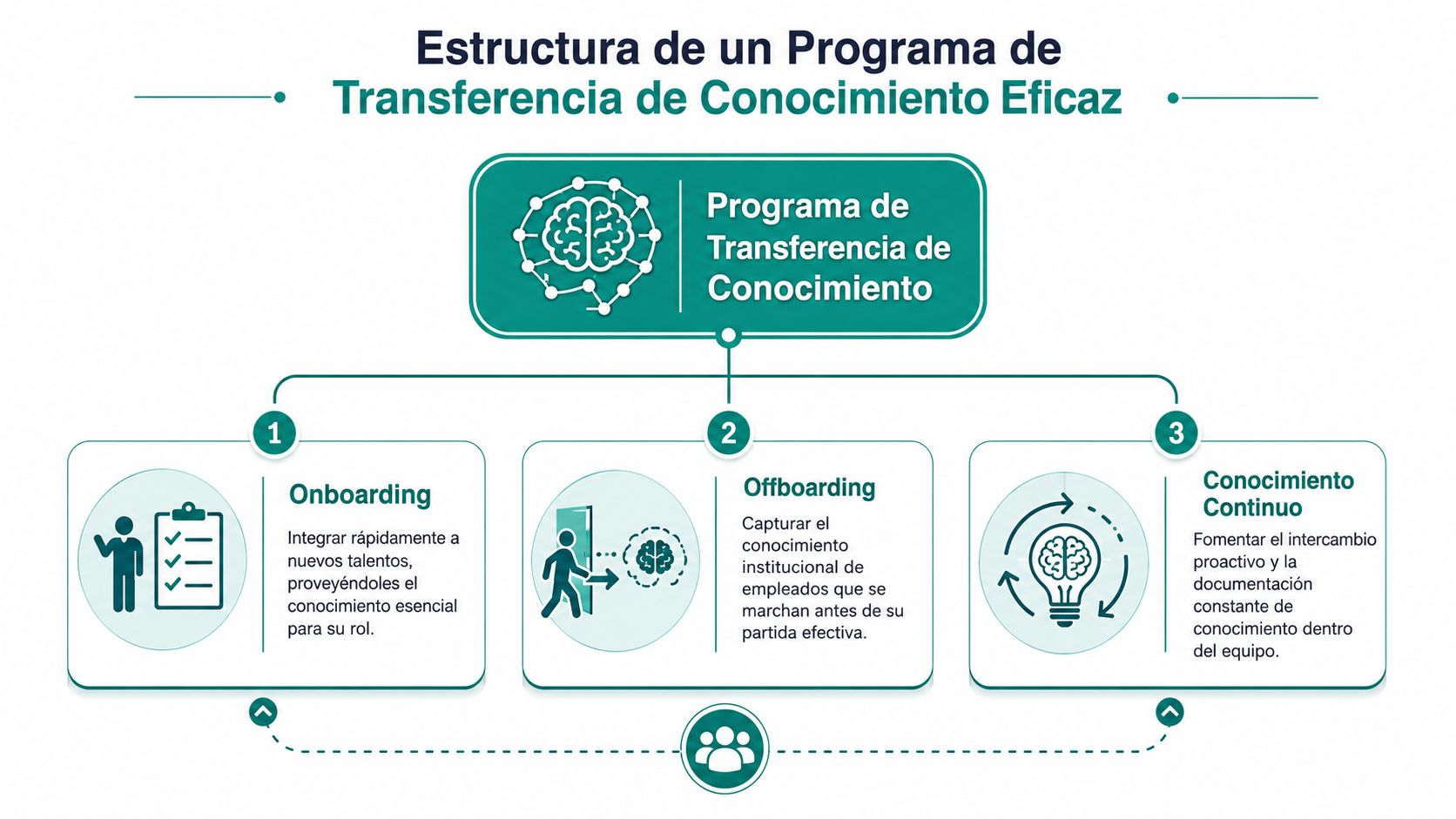
Onboarding que reduce dependencia
El onboarding técnico suele fallar por exceso de amplitud. Se da demasiada información y muy poco criterio. Un ingeniero nuevo no necesita leerlo todo. Necesita saber qué debe entender primero para ser útil sin romper nada.
Yo estructuro este pilar con pocas piezas, pero muy claras:
- Mapa del sistema. Servicios, repositorios, owners y dependencias críticas.
- Guía por rol. Qué debe dominar en las primeras semanas y qué puede esperar.
- Buddy técnico. Una persona accesible para preguntas reales, no solo para acompañamiento formal.
- Primeras tareas con contexto. No tickets sueltos. Cambios pequeños que obliguen a recorrer el flujo real.
Aquí la decisión difícil es recortar. Si metes veinte documentos y diez vídeos, la gente no prioriza. Si ofreces una ruta mínima y bien escogida, el aprendizaje se vuelve operativo.
Offboarding que captura el porqué
El offboarding no es pedir “deja todo documentado”. Eso casi siempre produce documentos apresurados y poco útiles. Lo que necesitas es forzar una extracción de contexto con estructura.
Lo que mejor funciona suele ser esto:
- Inventario de áreas críticas que toca esa persona.
- Sesiones de handover grabadas por dominio, no por lista de tareas.
- Riesgos abiertos. Qué está inestable, qué depende de deuda técnica, qué decisiones están pendientes.
- Shadowing inverso. La persona entrante o el equipo receptor explica de vuelta cómo operaría esa parte.
Ese último punto es el que más se omite. Y es el que te dice si hubo transferencia real o solo exposición a información.
Si el receptor no puede tomar una decisión razonable con el contexto recibido, el handover no ha terminado.
Conocimiento continuo que evita el modo pánico
El mejor knowledge transfer ocurre antes de que haya urgencia. Si no existe ese tercer pilar, conviertes cada salida, cambio de equipo o incidente serio en un ejercicio de rescate.
Algunas prácticas ligeras sí merecen quedarse en la rutina:
- ADRs breves para decisiones de arquitectura.
- Post-mortems útiles que expliquen causa, contexto y cambio aplicado.
- Rotaciones por sprint en áreas sensibles como observabilidad, despliegues o data pipelines.
- Demos internas técnicas cuando un equipo resuelve algo que otros van a reutilizar.
- Pairing puntual en componentes con demasiado conocimiento concentrado.
No hace falta montar una universidad interna. Hace falta integrar el intercambio de contexto en el trabajo normal. Cuando el conocimiento circula de forma continua, el offboarding deja de ser una carrera contra el reloj.
Herramientas y plantillas para ejecutar tu plan
No necesitas comprar una suite específica para hacer knowledge transfer decente. Necesitas usar bien herramientas que probablemente ya tienes. El error habitual no es de software. Es de diseño. Se crean repositorios enormes sin criterio de acceso, plantillas inconsistentes y documentos que nadie actualiza.
La base central puede vivir en Notion o Confluence. Ambas sirven. La diferencia la marca la estructura. Si abres cualquiera de esas herramientas y todo depende de búsquedas libres o carpetas ambiguas, has creado un archivo, no un sistema.
Qué herramientas sí aportan valor
Para una startup, esta combinación suele ser suficiente:
- Notion o Confluence para base de conocimiento central. Úsalos para guías por rol, mapas de sistemas, runbooks, ADRs y FAQs técnicas.
- GitHub o GitLab para que ADRs, documentación cercana al código y post-mortems técnicos vivan donde trabajan los ingenieros.
- Loom o CleanShot para capturar conocimiento tácito. Un vídeo corto recorriendo un flujo complejo suele transferir mejor que páginas de texto.
- Slack con canales por dominio. No como repositorio final, sino como capa de conversación y resolución rápida.
- Matriz RACI o similar para dejar claro ownership. Si nadie mantiene un activo de conocimiento, ese activo se pudre. Una matriz de responsabilidad bien definida evita ese vacío.
La literatura sobre equipos distribuidos insiste en que la transferencia efectiva necesita bidireccionalidad y agilidad, no un flujo unidireccional de experto a receptor, como resume la investigación publicada en Organization Science. En remoto o híbrido esto importa el doble. La documentación tiene que abrir conversación, no cerrarla.
Plantillas mínimas que sí merece la pena crear
No intentes plantillar todo. Plantilla lo que se repite y lo que genera ambigüedad cuando falta.
Crea estas cuatro primero:
- ADR
Contexto, decisión, alternativas descartadas, consecuencias y fecha. - Post-mortem
Qué pasó, por qué pasó, cómo se detectó, qué señales se ignoraron y qué cambió después. - Guía de onboarding por rol
Repositorios, servicios, accesos, primeros tickets, riesgos frecuentes, personas de referencia. - Checklist de offboarding
Sistemas bajo ownership, riesgos abiertos, sesiones grabadas, documentación pendiente, contactos clave.
Checklist de offboarding para copiar mañana
Si un tech lead tuviera que ejecutar un offboarding mañana mismo, usaría algo así:
- Lista de dominios. Qué áreas controla realmente la persona saliente.
- Estado operativo. Qué servicios, jobs, dashboards o pipelines requieren atención especial.
- Decisiones vivas. Qué debates siguen abiertos y qué opciones ya se descartaron.
- Conocimiento tácito. Qué “trucos”, validaciones manuales o señales informales usa esa persona.
- Grabaciones cortas. Una por sistema crítico, centradas en flujos reales.
- Transferencia inversa. El receptor explica cómo actuaría ante un cambio o un incidente.
- Última revisión. El manager o tech lead valida que no se ha quedado nada crítico sin owner.
Si no puedes mantener esto actualizado, simplifícalo más. La plantilla perfecta que nadie usa vale menos que una plantilla pequeña que el equipo sí rellena.
Knowledge transfer aplicado a ingeniería, datos y AI
El knowledge transfer falla cuando se trata igual a todos los equipos. No se transfiere del mismo modo el contexto de una arquitectura backend, la lógica de un modelo de atribución o los experimentos descartados en un sistema de ML. La forma cambia porque cambia el tipo de conocimiento y el riesgo de perderlo.
Ingeniería de software
Se va tu senior de backend. Lo peligroso no es perder acceso al código. El código sigue ahí. Lo peligroso es perder el porqué. Por qué un servicio tiene esa frontera, por qué se eligió consistencia eventual, por qué cierto endpoint no debe tocarse sin revisar tres dependencias antiguas.
En ingeniería, la transferencia útil ocurre cerca del trabajo real:
- ADRs en el repositorio para decisiones de arquitectura.
- Pull requests usados como espacio de explicación, no solo de validación.
- Runbooks para incidentes recurrentes.
- Walkthroughs grabados de componentes especialmente sensibles.
Un buen test es simple. Si otro ingeniero puede modificar una pieza sin reabrir errores ya resueltos, hubo transferencia. Si solo puede seguir pasos mecánicos, no.
Datos
Ahora piensa en el único data scientist o analytics engineer del equipo. Si se va, el riesgo no está solo en los dashboards. Está en las definiciones, en las transformaciones, en las excepciones y en los supuestos que nadie explicitó.
Aquí conviene dejar trazabilidad en artefactos concretos:
- Linaje de datos documentado en dbt o en la herramienta que uses.
- Diccionario de métricas compartido con negocio.
- Supuestos de calidad y checks críticos.
- Notas sobre datasets conflictivos y casos donde una métrica cambia según contexto.
Para muchos equipos, contratar o sustituir este perfil ya es difícil de por sí. Si además el contexto está disperso, el coste sube. Por eso tiene sentido revisar cómo se define el rol de ingeniero de datos y qué conocimiento operativo debe dejar encapsulado desde el primer día.
AI y machine learning
En AI el problema se multiplica porque gran parte del valor está en experimentación, criterio y descarte. La transferencia no se mide por cuántos documentos dejó el equipo. Se mide por la capacidad de aplicar ese conocimiento en contextos nuevos, lo que la literatura sobre transferencia llama transferencia lejana, según el documento de ISA sobre preserving your secret sauce.
Eso obliga a registrar más que el modelo final:
- Experimentos fallidos y por qué fallaron.
- Hipótesis descartadas.
- Criterios de evaluación usados de verdad, no solo la métrica final.
- Dependencias del pipeline y decisiones de serving.
- Casos borde donde el modelo se comporta mal.
En AI, un manual rara vez basta. Si el equipo no puede comparar enfoques, repetir pruebas y entender descartes, el conocimiento no se ha transferido.
Herramientas como MLflow o Weights & Biases ayudan porque convierten decisiones dispersas en trazas consultables. Pero, otra vez, la herramienta no hace el trabajo sola. Lo hace el hábito de dejar contexto útil.
Cómo medir el éxito y evitar los errores comunes
El anti-patrón más común en knowledge transfer es este: el equipo mide actividad, no impacto. Cuenta documentos creados, sesiones hechas y carpetas organizadas. Luego descubre que la gente sigue preguntando lo mismo, que onboarding sigue siendo lento y que ciertos incidentes dependen siempre de las mismas personas.
La señal más clara de este fallo ya está documentada. El 58% de los proyectos de KT fallan por sobreconfiar en la documentación explícita, ignorando el conocimiento tácito de los expertos, y eso provoca un 30% de retrabajos en los primeros tres meses de un nuevo ingeniero, según el análisis de IMD sobre knowledge transfer. Si solo produces documentos, puedes estar fabricando una falsa sensación de control.
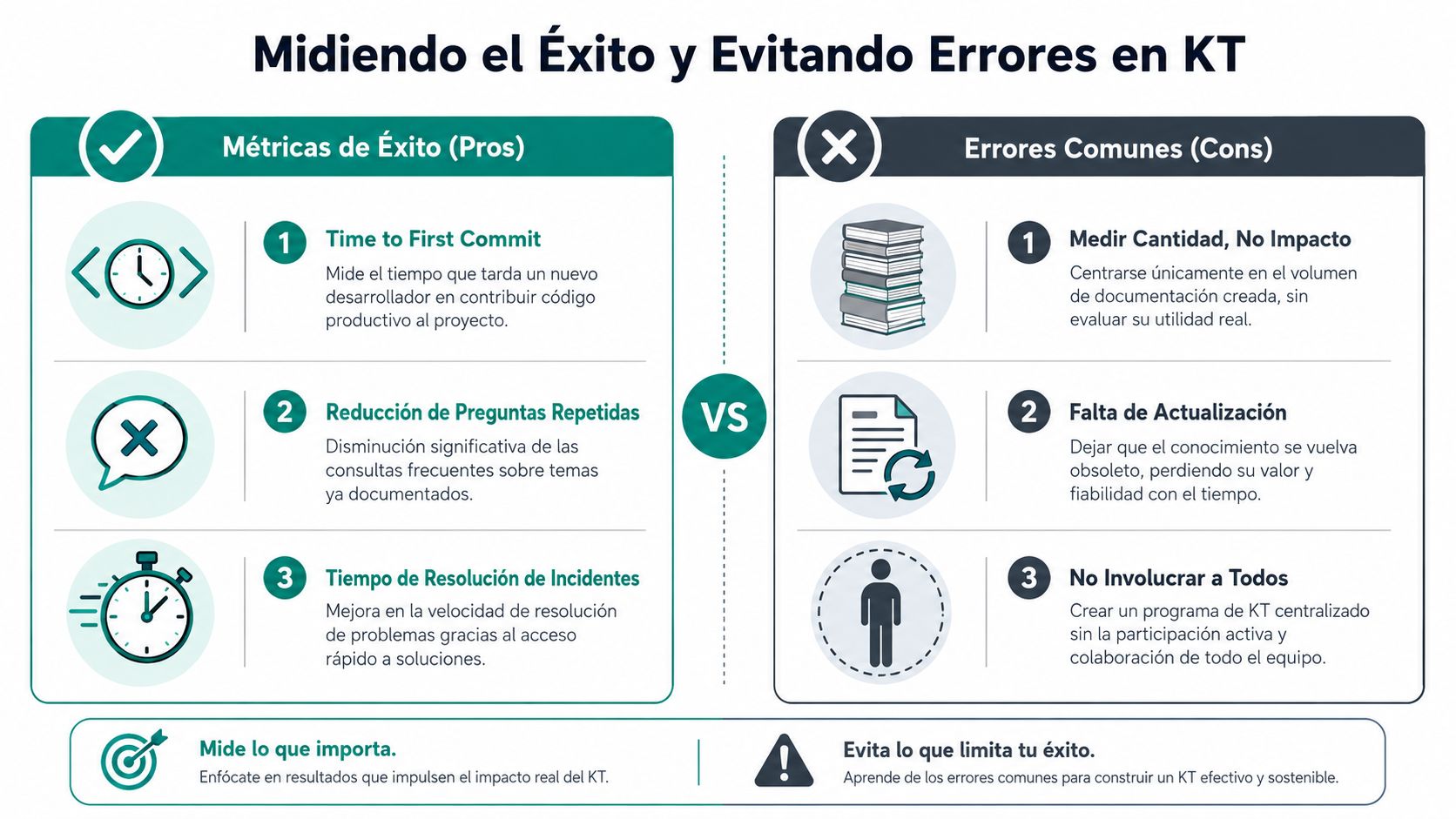
Métricas que sí pondría en un dashboard
No hace falta construir un sistema de medición enorme. Hace falta elegir pocas métricas que revelen si el conocimiento se puede usar.
- Time to First Commit. Cuánto tarda una persona nueva en aportar código útil.
- Tiempo hasta autonomía operativa. Cuándo deja de depender de ayuda constante para su área.
- Preguntas repetidas por dominio. Si el mismo tema reaparece cada semana, el conocimiento no está accesible o no se entiende.
- Cobertura de ownership. Qué áreas críticas tienen responsable claro de contenido y mantenimiento.
- Resolución de incidentes en áreas sensibles. Si solo una persona resuelve rápido, sigue habiendo concentración de conocimiento.
Estas métricas no son perfectas. Pero sí te obligan a mirar el problema donde duele: velocidad, dependencia y capacidad de ejecución.
Errores que conviene cortar pronto
He visto estos una y otra vez:
- Documentarlo todo. Mala idea. Acabas con ruido, no con claridad.
- No asignar owners. El conocimiento sin responsable envejece rápido.
- Hacer KT solo en offboarding. Reaccionas tarde y bajo presión.
- Separar demasiado documento y práctica. Si no hay aplicación, no hay transferencia real.
- Convertir sesiones en monólogos. Si el receptor no pregunta, prueba y devuelve comprensión, no estás validando nada.
El conocimiento útil no es el que está escrito. Es el que otro miembro del equipo puede aplicar sin depender del autor original.
La decisión difícil
Siempre hay una tensión real entre velocidad y mantenimiento del conocimiento. En una startup, esa tensión no desaparece. Lo que cambia es cómo la gestionas. Mi postura es clara: no documentes más, documenta mejor y acopla esa documentación a rituales concretos.
Eso significa que en retrospectivas, post-mortems, revisiones de arquitectura y cambios de ownership tiene que existir una pregunta fija: qué hemos aprendido, quién necesita saberlo y dónde va a vivir. Si esa pregunta no forma parte del trabajo normal, el knowledge transfer queda relegado a “cuando haya tiempo”. Y nunca lo hay.
Si estás escalando equipo y ves que el conocimiento crítico depende de demasiado pocas personas, merece la pena corregirlo antes de abrir nuevas vacantes. En Kulturo trabajamos con CTOs, founders y tech leads que necesitan reforzar equipos de ingeniería, datos y AI sin perder contexto operativo por el camino. Si necesitas incorporar talento técnico con criterio de startup, no solo CVs, podemos ayudarte.


.png)

