
15.06.2026
Kubernetes Deployment: Guía práctica de producción 2026
Guía de kubernetes deployment con ejemplos reales
Pedro Cailá

Si estás en una startup que ya pasó la fase de “levantamos un contenedor y listo”, probablemente tienes este problema: cada release toca algo distinto, una actualización rompe tráfico, nadie sabe si el fallo viene de la app o del clúster, y escalar empieza a sentirse improvisado. Ahí es donde un buen kubernetes deployment deja de ser una pieza técnica más y pasa a ser una disciplina operativa.
Kubernetes ya no es una apuesta temprana. Más del 60% de las empresas ya lo han adoptado, y en compañías de más de 1.000 empleados la adopción supera el 91%, según estas estadísticas de adopción y mercado de Kubernetes recopiladas por Tigera. El mismo análisis sitúa el mercado en 1,46 mil millones de USD en 2021, 1,8 mil millones de USD en 2022 y una proyección de 9,69 mil millones de USD en 2031. La lectura práctica es simple. Si estás profesionalizando infraestructura, Kubernetes ya forma parte del estándar esperado.
El error habitual en equipos pequeños no es usar Kubernetes. Es usarlo como si fuera Docker con más YAML. Un clúster aguanta eso durante un tiempo. En cuanto suben los despliegues, los entornos o la presión de entrega, deja de aguantarlo.
Qué es un Kubernetes Deployment y por qué lo necesitas
Un Deployment no sirve solo para arrancar contenedores. Sirve para declarar cómo quieres que viva una aplicación en el clúster. Ese matiz importa mucho.
Un Pod aislado te puede servir para pruebas, depuración o tareas muy puntuales. En producción, es una mala base operativa. Si el Pod cae, si el nodo falla o si necesitas actualizar versión sin cortar tráfico, un Pod por sí solo no te da una historia completa.
En cambio, un Deployment actúa como un supervisor. Define cuántas réplicas quieres, qué imagen deben ejecutar, cómo se actualizan y qué estado debe mantenerse. Kubernetes se encarga de perseguir ese estado deseado y, para hacerlo, usa un ReplicaSet por debajo.
La diferencia que sí cambia operaciones
La diferencia entre “tengo un contenedor corriendo” y “tengo un servicio desplegado” suele ser exactamente esta:
- Reemplazo automático si un Pod desaparece
- Escalado horizontal sin recrear todo a mano
- Rollouts controlados cuando cambias versión
- Consistencia declarativa para que staging y producción no diverjan por accidente
Un Deployment no describe una ejecución puntual. Describe un contrato operativo.
Para una startup o scaleup, eso evita uno de los peores patrones de crecimiento: cada ingeniero despliega de una forma distinta, con defaults distintos y sin una política clara de recuperación.
Cuándo deja de ser opcional
En cuanto cumples varias de estas condiciones, necesitas estandarizar Deployments de verdad:
- Tienes varias releases por semana y no quieres revisar manualmente cada cambio.
- Tu aplicación ya corre con varias réplicas y un reinicio simple ya no basta.
- Empiezas a separar responsabilidades entre backend, plataforma, SRE o DevOps.
- Necesitas trazabilidad para saber qué versión está viva y por qué.
Si tu servicio es stateless, Deployment es el controlador natural. Y si no lo estás usando así, probablemente estás asumiendo riesgo innecesario.
Creando tu primer Deployment con YAML
La documentación oficial de Kubernetes deja claro que un Deployment se define de forma declarativa y debe incluir al menos .apiVersion, .kind y .metadata. También indica que su función principal es gestionar Pods mediante un ReplicaSet y que el rollout es la vía estándar para actualizarlos de forma controlada, como explica la documentación oficial sobre Deployments de Kubernetes.
Un ejemplo mínimo y útil para producción temprana sería este:
apiVersion: apps/v1kind: Deploymentmetadata:name: nginx-weblabels:app: nginx-webspec:replicas: 3selector:matchLabels:app: nginx-webtemplate:metadata:labels:app: nginx-webspec:containers:- name: nginximage: nginx:stableports:- containerPort: 80
Qué hace cada bloque
apiVersion indica qué versión de API usa el recurso. Para Deployments, normalmente será apps/v1.
kind define el tipo de objeto. Aquí es Deployment. Parece trivial, pero evita uno de los errores clásicos al copiar manifiestos entre recursos.
metadata guarda identidad y etiquetas. El name te permite operar luego con kubectl, y los labels ayudan a relacionar recursos entre sí.
Dónde se juega la operativa
La parte importante está en spec.
replicasdice cuántos Pods quieres en ejecución.selector.matchLabelsdefine qué Pods pertenecen a este Deployment.templatedescribe el Pod que Kubernetes debe crear.-
Si selector y las labels del template no coinciden, el Deployment queda mal definido. Ese fallo no es raro en equipos que editan YAML a mano y hacen copy-paste entre servicios.
Regla práctica: el selector debe ser pequeño, estable y obvio. No metas labels decorativas en esa decisión.
Dentro de template.spec.containers, defines la imagen, puertos y más adelante añadirás recursos, probes y contexto de seguridad. Ese bloque es la plantilla real de cada réplica.
Cómo aplicarlo y comprobarlo
Guarda el archivo, por ejemplo, como deployment.yaml, y aplícalo así:
kubectl apply -f deployment.yaml
Después valida que los Pods se han creado:
kubectl get pods
Y revisa el Deployment:
kubectl get deployments
Si estás empezando, no corras a meter Helm, Kustomize, Argo CD o Flux desde el minuto uno. Primero asegúrate de que el equipo entiende bien la anatomía básica del recurso. La mayoría de los problemas de un kubernetes deployment no vienen por falta de tooling. Vienen por no entender qué está declarando realmente el manifiesto.
Gestión del ciclo de vida actualizar y escalar
Una vez desplegado el servicio, el trabajo real empieza con dos operaciones repetidas: actualizar sin romper tráfico y escalar sin improvisar. Las dos parecen simples. Solo una lo es si el manifiesto está bien diseñado.
Cómo actualizar sin cortar servicio
El patrón estándar es cambiar la imagen del contenedor y volver a aplicar el YAML. Por ejemplo:
containers:- name: nginximage: nginx:1.27
Luego:
kubectl apply -f deployment.yaml
Eso dispara un rolling update. Kubernetes crea Pods nuevos y retira los antiguos de forma gradual. No hace magia. Sigue las reglas que tú definas.
Un ejemplo útil:
strategy:type: RollingUpdaterollingUpdate:maxSurge: 1maxUnavailable: 1
Si tienes replicas: 3, maxSurge: 1 permite crear una réplica extra temporal durante la actualización. maxUnavailable: 1 permite que una réplica no esté disponible en ese proceso. Es una configuración razonable para muchos servicios web pequeños.
Dónde se equivocan muchos equipos
El error no suele estar en usar rolling update. Está en dejar los valores por defecto sin pensar en la capacidad real del clúster.
- Clúster ajustado. Si no tienes margen de CPU o memoria,
maxSurgepuede bloquear la actualización porque no hay sitio para la réplica extra. - Servicio sensible a latencia. Si permites demasiada indisponibilidad, tu balanceador puede quedarse con menos Pods sanos de los que pensabas.
- App que arranca lento. Si no has definido readiness correctamente, Kubernetes puede considerar listo un Pod que aún no debería recibir tráfico.
Si estás construyendo equipo de plataforma o DevOps, conviene tener claro qué responsabilidades cubre ese rol. Este desglose sobre qué hace un ingeniero DevOps encaja bien con la realidad de quien acaba operando estos despliegues.
Escalar sin tocar la plantilla
Para subir o bajar réplicas rápido:
kubectl scale deployment nginx-web --replicas=5
Eso modifica el estado deseado del Deployment y el ReplicaSet crea o elimina Pods hasta alcanzarlo.
Si necesitas cambiar réplicas constantemente a mano, no tienes un problema de comando. Tienes un problema de estrategia de escalado.
En startups, el escalado manual es aceptable al principio. En cuanto el patrón de carga deja de ser predecible, conviene pasar a una política más formal. Pero incluso antes de hablar de HPA, un Deployment bien definido ya te da una base mucho más estable que cualquier script ad hoc.
Estrategias de despliegue más allá del rolling update
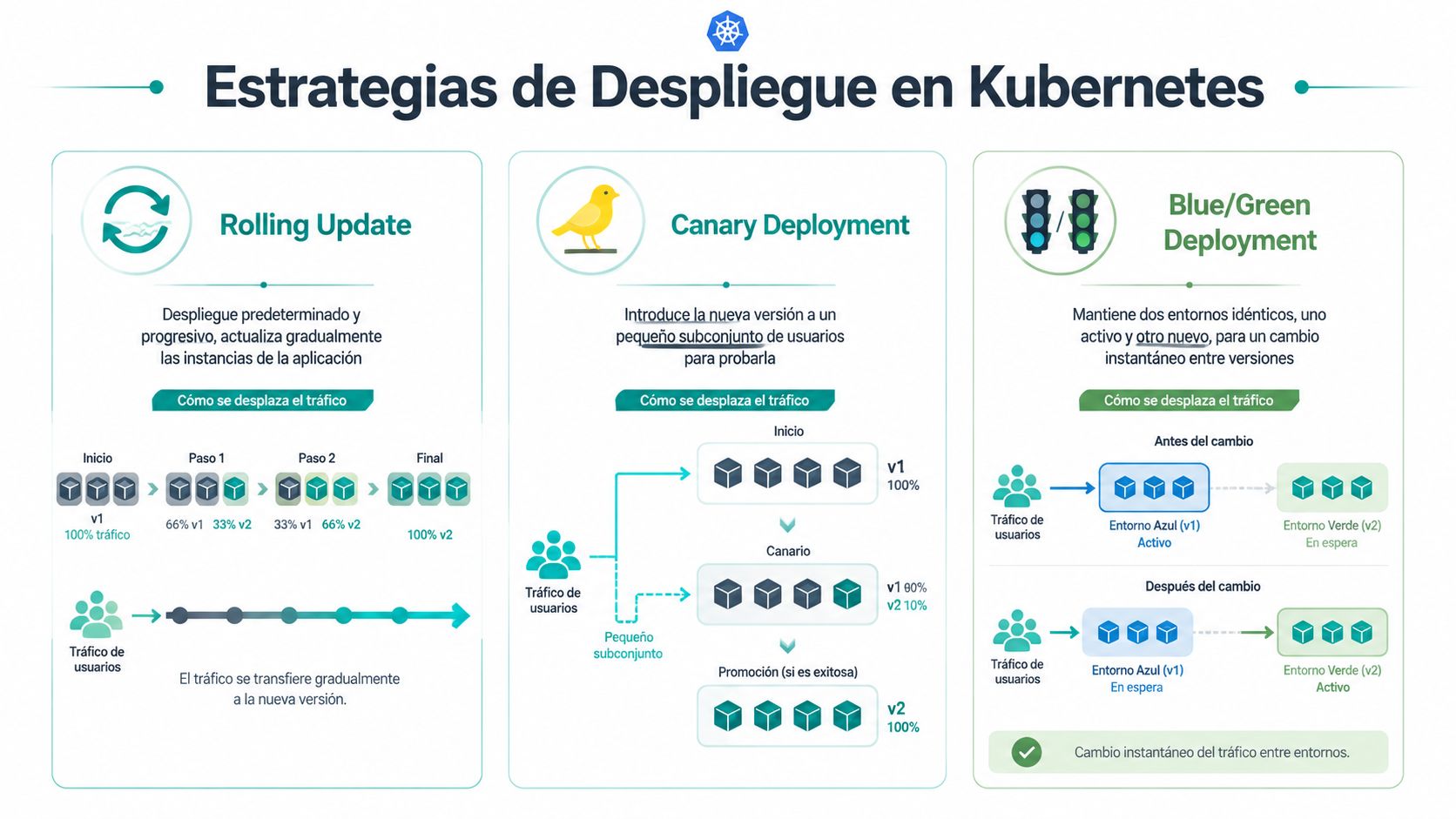
La mayoría de equipos conoce tres nombres. Rolling update, blue/green y canary. El problema es que muchas comparativas se quedan en la teoría y no ayudan a decidir en un entorno con presupuesto limitado, poca capacidad o un equipo de plataforma pequeño.
La referencia útil aquí no es “qué estrategia es más avanzada”, sino “qué estrategia puedes operar bien”.
Rolling update cuando la sencillez gana
Rolling update es el default por una razón. Tiene una relación muy buena entre simplicidad, consumo de recursos y continuidad de servicio.
Para muchas startups, esta es la mejor elección cuando:
- El servicio es stateless
- El equipo no tiene observabilidad madura
- El clúster va justo de capacidad
- La frecuencia de despliegue es alta y necesitas rutina, no ceremonia
Con probes bien configuradas y recursos definidos, rolling update suele resolver el problema correcto sin meter una capa extra de complejidad.
Blue green cuando el cambio debe ser casi instantáneo
Blue/green mantiene dos entornos equivalentes. Uno sirve tráfico. El otro recibe la nueva versión. Cuando validas, cambias el tráfico.
Esto reduce riesgo operativo en releases delicadas. También facilita rollback rápido porque la versión anterior sigue viva. El coste es evidente. Necesitas capacidad duplicada y una forma clara de conmutar tráfico sin errores.
Si tu clúster ya va apretado, blue/green puede convertirse en una estrategia bonita en PowerPoint y muy cara en producción.
Canary cuando sí puedes medir bien
Canary expone la nueva versión a una parte pequeña del tráfico y te permite observar comportamiento antes de ampliar. Es potente, pero castiga a los equipos que no tienen una base de métricas, logs y alertas razonable.
Según esta guía sobre trade-offs entre estrategias de despliegue en Kubernetes, canary y blue/green reducen el riesgo de downtime, pero requieren más recursos duplicados y monitorización sólida. La misma guía sostiene que, para muchas startups, un rolling update bien ajustado con límites de recursos y readiness probes puede ser superior a canary o blue/green cuando el equipo es pequeño y el clúster es ajustado.
Mi criterio para startups y scaleups
No empieces por la estrategia más sofisticada. Empieza por la que puedas sostener sin deuda operativa.
- Usa rolling si tu prioridad es velocidad con disciplina básica.
- Usa blue/green si el coste de una versión mala es alto y puedes pagar duplicidad temporal.
- Usa canary si ya tienes señales fiables para detectar regresiones pronto.
Elegir una estrategia demasiado compleja para tu nivel de operación no reduce riesgo. Lo cambia de sitio.
He visto más equipos sufrir por un canary mal observado que por un rolling update conservador. En una scaleup, el objetivo no es parecer madura. Es serlo en las partes que ya tocas cada semana.
Observabilidad y debugging de un Deployment en producción
Desplegar no es el final. En producción, un kubernetes deployment solo está bien si puedes entender rápido qué está pasando cuando deja de comportarse como esperas.
Empieza por kubectl. Sigue siendo la herramienta más útil para el primer diagnóstico.
Comandos que sí resuelven problemas
Para revisar el estado general:
kubectl get deploymentskubectl get pods -o wide
Para ver eventos, condiciones y cambios recientes de un Deployment:
kubectl describe deployment nginx-web
Para revisar la salida del contenedor:
kubectl logs <pod-name>
Si necesitas entrar dentro para una comprobación puntual:
kubectl exec -it <pod-name>, bash
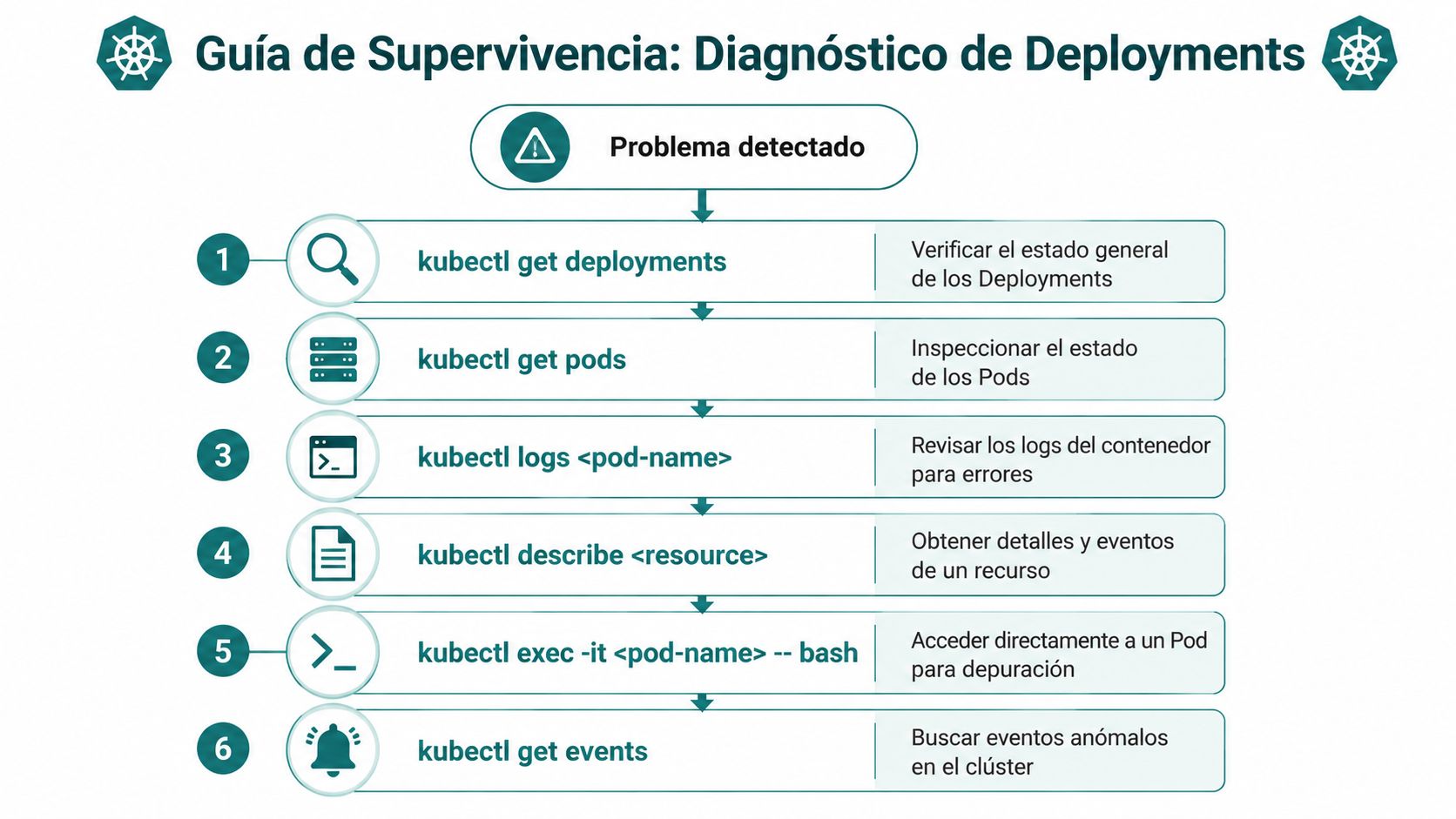
Los equipos que hacen buen debugging no son los que memorizaron más comandos. Son los que saben leer señales en orden. Primero estado del Deployment. Luego estado real de Pods. Luego eventos. Luego logs.
Si estás formalizando calidad operativa, este enfoque conecta bien con una cultura de testing automatizado. Cuanto mejor validas antes del despliegue, menos debugging reactivo haces en producción.
Readiness y liveness no son lo mismo
Aquí hay mucha confusión. Y cuesta incidents.
- Readiness probe decide si un Pod debe recibir tráfico.
- Liveness probe decide si el contenedor debe reiniciarse porque está roto.
No intercambies sus funciones. Una app puede estar viva pero no lista. Por ejemplo, arrancó el proceso pero aún no completó inicialización, migraciones o warm-up de caché.
Ejemplo:
readinessProbe:httpGet:path: /readyport: 80livenessProbe:httpGet:path: /healthport: 80
Lo mínimo no negociable
La guía de buenas prácticas de Kubernetes en Spacelift insiste en algo que comparto por completo: configurar requests/limits, readiness/liveness probes y aplicar cambios con GitOps reduce sobreconsumo de recursos y despliegues defectuosos. También recomienda integrar los contenedores en recursos como Deployment o StatefulSet en lugar de operar Pods sueltos.
Señal útil: si el rollout “termina” pero el servicio falla, casi siempre reviso readiness antes que la imagen.
Después de kubectl, el siguiente nivel natural es Prometheus para métricas y Grafana para visualización. No porque hagan la plataforma más moderna, sino porque sin series temporales es difícil distinguir entre un fallo puntual, una degradación sostenida y una actualización mala.
Buenas prácticas de seguridad y rendimiento
Muchos equipos separan seguridad y velocidad como si fueran fuerzas opuestas. En Kubernetes, esa separación suele salir cara. El problema no es endurecer el despliegue. El problema es hacerlo tarde, cuando el clúster ya tiene excepciones por todas partes.
Según el resumen de Red Hat sobre adopción, seguridad y tendencias de contenedores, el 67% de los encuestados retrasó o ralentizó despliegues por preocupaciones de seguridad. Además, casi la mitad reportó efectos adversos como pérdida de ingresos o multas derivadas de incidentes de seguridad y cumplimiento. Eso encaja perfectamente con lo que pasa en startups. La deuda de seguridad termina impactando release velocity.
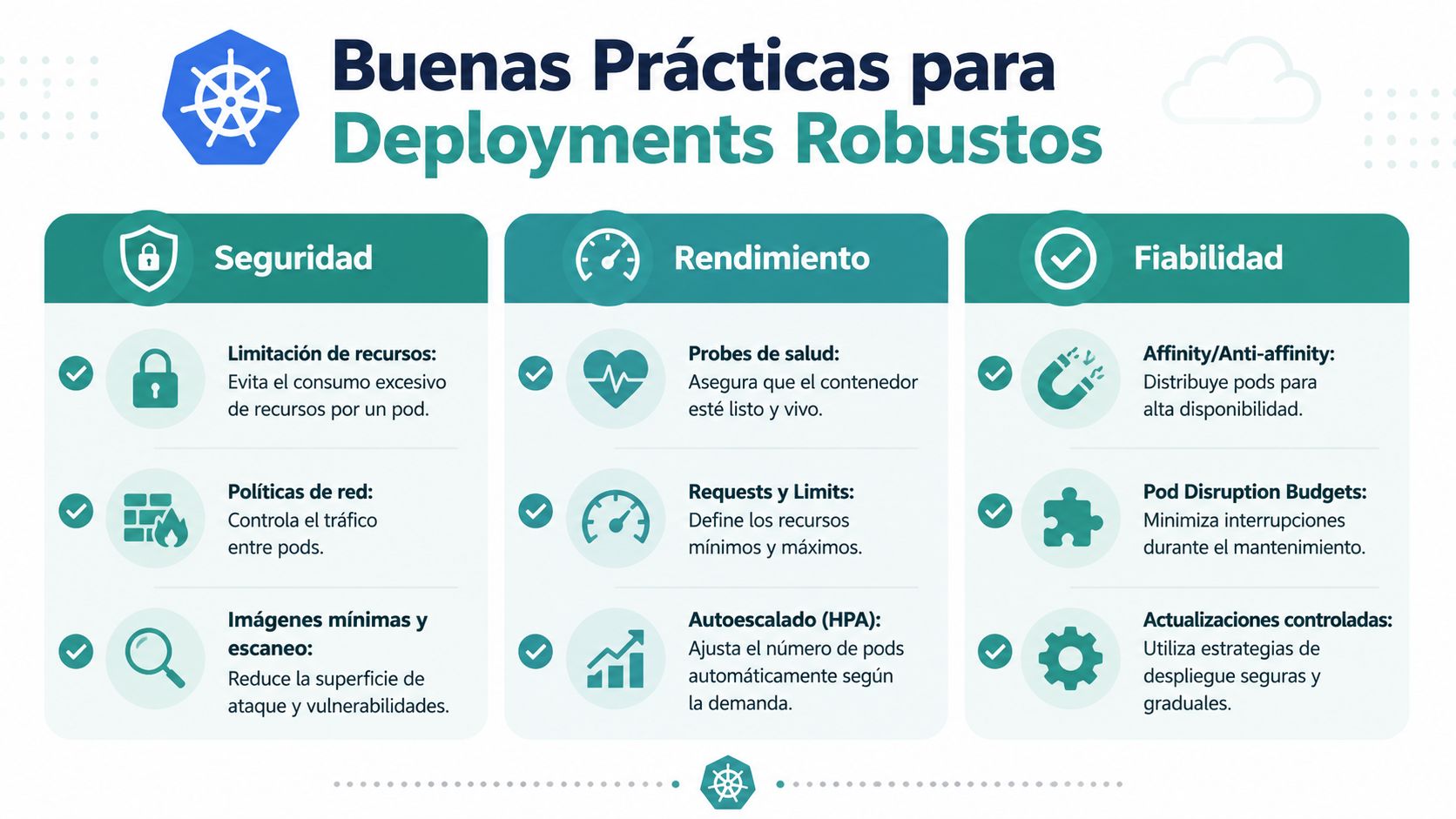
Recursos primero
Si no defines requests y limits, estás dejando que un servicio se comporte bien solo por buena voluntad. Eso no escala.
Un contenedor sin límites puede comerse recursos del nodo y degradar otros workloads. Un contenedor sin requests complica planificación y hace menos predecible el clúster.
Usa algo así como punto de partida:
resources:requests:cpu: "100m"memory: "128Mi"limits:cpu: "500m"memory: "512Mi"
No busques valores perfectos en el primer commit. Busca valores explícitos y revísalos con datos.
Seguridad que cabe en el manifiesto
Hay dos medidas simples que deberían ser habituales en casi cualquier servicio:
- Ejecutar como usuario no root
- Usar filesystem raíz de solo lectura cuando sea viable
Ejemplo:
securityContext:runAsNonRoot: truereadOnlyRootFilesystem: true
No solucionan todo. Sí reducen superficie de ataque de forma inmediata. Si tu equipo necesita reforzar estas prácticas a nivel organizativo, suele ser buena señal contar con expertos en ciberseguridad que entiendan entornos cloud native, no solo seguridad genérica.
GitOps cuando quieres dejar de discutir sobre el estado real
GitOps con Argo CD o Flux no es una moda. Es una respuesta a un problema muy concreto: nadie sabe si producción refleja lo que hay en Git o lo que alguien tocó a mano.
Con GitOps ganas tres cosas:
- Trazabilidad de quién cambió qué
- Repetibilidad entre entornos
- Auditoría sin depender de memoria tribal
Si puedes cambiar producción sin que ese cambio pase por Git, antes o después tendrás una divergencia que costará una tarde entera.
En una startup pequeña, esto puede empezar siendo muy simple. Un repositorio claro, overlays por entorno y una política estricta de no tocar recursos manualmente salvo emergencia. Lo importante no es implantar la versión más completa de GitOps. Es cerrar la puerta al caos operativo.
Preguntas Frecuentes sobre Kubernetes Deployments
Cómo revierto un despliegue fallido
Usa:
kubectl rollout undo deployment <nombre>
Eso revierte al revisionado anterior del Deployment. Es una red de seguridad útil, pero no debería ser tu plan principal. Si haces rollback a menudo, revisa probes, estrategia de rollout y validaciones previas al despliegue.
Puede un Deployment gestionar aplicaciones con estado
La respuesta corta es que no deberías usarlo para eso. Un Deployment está pensado para cargas normalmente sin estado. Bases de datos, colas persistentes o sistemas que dependen de identidad estable de Pods encajan mejor con StatefulSet.
Forzar una base de datos dentro de un Deployment suele funcionar hasta que necesitas garantías reales sobre almacenamiento, orden de arranque o identidad persistente. Y ese “hasta” llega rápido.
Qué pasa si despliego en edge o con conectividad intermitente
Aquí cambia el diseño. No basta con repetir el patrón de cloud centralizado.
La guía de despliegue de Kubernetes en edge de Plural recomienda diseñar para desconexión, distribución multi-cluster y usar distribuciones ligeras como K3s, porque el hardware suele ser limitado. Ese consejo es especialmente útil si operas retail, logística, sucursales o entornos IoT.
En edge, las preguntas importantes son otras:
- Cómo mantiene autonomía el nodo cuando pierde enlace
- Cómo sincronizas configuración e imágenes
- Cómo reduces dependencia del plano de control central
Un kubernetes deployment bien hecho en edge no es solo un YAML aplicado lejos. Es una decisión de arquitectura orientada a tolerar conectividad imperfecta.
Si estás escalando equipo y necesitas incorporar perfiles capaces de operar Kubernetes en producción, desde DevOps y Platform Engineering hasta SRE o seguridad cloud, Kulturo ayuda a startups y scaleups en España a contratar talento técnico especializado con rapidez y criterio.


.png)

